

Ajuste demográfico por imputación
Demographic adjustment by imputation
Benito Durán Romo
Instituto Nacional de Estadística y Geografía, benito.duran@inegi.org.mx
Nota: el autor agradece la participación de Adriana Pérez Amador, Olinca Páez Domínguez y Lilia Guadalupe Luna Ramírez en el proceso de investigación y de integración de este documento.
Vol. 9 número especial 2018 – Epub Ajuste demográfico… – Epub

|
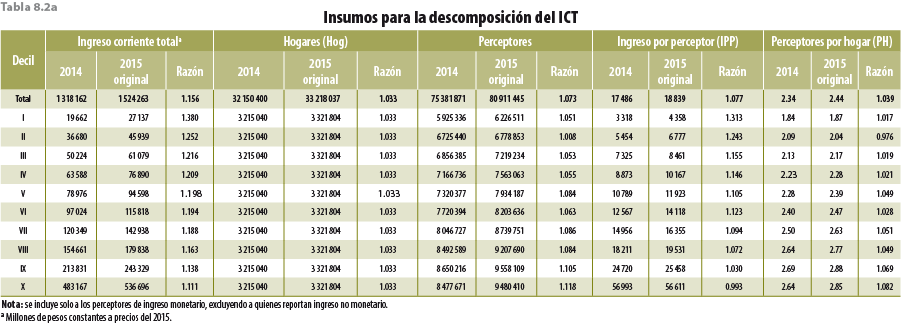
Un aumento inusual en el número de hogares reportado por el Módulo de Condiciones Socioeconómicas (MCS) 2015 se explica en parte por la contracción del tamaño del hogar y el consiguiente ajuste de factores de expansión para aumentar el volumen de la población con el objetivo de acercarse a las proyecciones del Consejo Nacional de Población (CONAPO). Esto también tuvo un efecto: aumentó el volumen de hogares, pero en este caso superó el número proyectado por el CONAPO (32 298 321, por debajo de los 33 218 037 reportados por el MCS 2015). Si en el MCS 2015 la contracción se debió a una omisión poblacional dentro del hogar durante la fase de encuestado, puede restaurarse el tamaño de los hogares con un cuidadoso proceso de imputación automática de individuos en ciertos hogares con base en la técnica de imputación Cold-Deck. Para lograrlo, se creó un gran grupo (pool) de donantes con las personas registradas en los MCS 2012 hasta 2015. Como resultado final, el proceso produce más individuos que en la base de datos original, requiriendo un reajuste de los factores de expansión, de acuerdo con la nueva estructura de población resultante de la imputación. En general, esto significa que los factores de expansión no tienen que ser tan grandes como los originales y, por lo tanto, se obtienen menos hogares. Con este procedimiento de imputación del MCS 2015, el número de hogares se redujo en poco más de 500 mil, con un tamaño del hogar de 3.71 y no 3.65 correspondiente al proceso original. Al comparar el ingreso actual con el MCS 2014, el monto total crece 14.1% (1.53% menos que el original), aunque el promedio por hogar crece 12.25% (0.32% más que el original). Palabras clave: Cold-Deck; imputación; individuos; hogares; encuesta; factores de expansión. |
An unusual increase in the number of households reported by the Socio-Economic Conditions Module 2015 (MCS 2015 by its Spanish acronym) is explained in part by the contraction of the household size and the consequent adjustment of weights to increase the volume of the population with the aim of approaching to the projections of National Council of Population (CONAPO by its Spanish acronym). This also had an effect: increased the volume of households, but in this case exceeded the number projected by CONAPO (32 298 321, below the 33 218 037 reported by the MCS 2015). If in the MCS 2015 the contraction was due to a population omission within the household during the survey phase, we can restore the size of the households with a careful process of automatic imputation of individuals in certain households, based on the ColdDeck imputation technique. To achieve this, a large pool of donors was created with the people recorded in the MCS 2012 until 2015. As a final result, the process produces more individuals than in the original database, requiring a readjustment of the weights, according to the new structure of the population resulting from imputation. In general, this means that the weights do not have to be as large as the original ones and therefore, fewer households are obtained. With this imputation procedure of MCS 2015, the number of households was reduced by just over 500 thousand, with a household size of 3.71 and not 3.65 corresponding to the original process. When comparing current income with MCS 2014, the total amount grows 14.1% (1.53% less than the original), although the average per household grows 12.25% (0.32% more than the original). Key words: Cold-Deck; imputation; individuals; households; survey; weights. |
1. Introducción
El Módulo de Condiciones Socioeconómicas (MCS) 2015 reportó un total de hogares casi al nivel del proyectado por el Consejo Nacional de Población (CONAPO) para el 2017, un poco más de 900 mil de lo que se tenía previsto para el 2015. Esto se debió a que el tamaño de hogar reportado por el MCS 2015 es menor de lo esperado y a que los factores de expansión de las encuestas son ajustados para llegar a un total de población, dejando de lado el número de hogares.
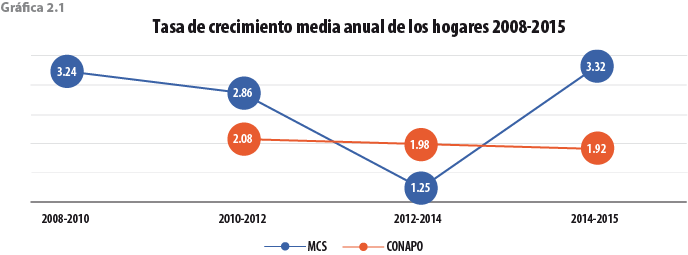
En la gráfica 1.1 se pueden observar las tasas de crecimiento de los hogares para distintas fuentes. En ésta notamos que mientras algunas encuestas del Instituto Nacional de Estadística y Geografía (INEGI) y las proyecciones del CONAPO reportaron tasas de crecimiento de los hogares menores a 2% entre el 2014 y 2015, el MCS la estimó 3.32% para el mismo periodo, es decir, 1.4% más que la del CONAPO, lo cual es una clara evidencia del crecimiento inusual de los hogares en el MCS 2015.

Ante esto, el objetivo de este ejercicio es incrementar el tamaño del hogar del MCS 2015 y, como consecuencia, acercar el total de hogares a lo proyectado por el CONAPO correspondiente a ese año. Para llevarlo a cabo, se diseñó un procedimiento de imputación de individuos a cierto número de hogares. De esta forma, se incrementa la población muestral del evento y, dado ese efecto, se reajustan los factores de expansión consiguiendo incrementar el tamaño del hogar y disminuir el total de hogares.
Cabe destacar que este proceso de imputación solo pretende hacer un ajuste demográfico al MCS 2015, lo cual no necesariamente se traduce en un ajuste en la distribución del ingreso y otras variables relacionadas con éste.
La sección Marco teórico se divide en dos partes, en la primera se presenta una de las posibles explicaciones de la baja en el tamaño del hogar del MCS 2015 y en la segunda parte se muestran algunas definiciones del proceso de imputación y su clasificación. Después, en Metodología se detalla el proceso completo de imputación aplicado a este caso, desde la forma de determinar el número de personas a imputar hasta llegar a la imputación como tal. Los resultados del procedimiento de imputación se dan en la sección correspondiente y, por último, se presentan comentarios respecto a la metodología y algunas conclusiones.
2. Marco teórico
2.1 Módulo de Condiciones Socioeconómicas
El MCS surge en el 2008 como el insumo para la medición multidimensional de la pobreza que por mandato de la Ley General de Desarrollo Social (LGDS) tiene que hacer el Consejo Nacional de Evaluación de la Política de Desarrollo Social (CONEVAL) y que, a la vez, obliga al INEGI a llevar a cabo los censos, conteos y encuestas necesarios para su medición. Desde ese año y hasta el 2014 los MCS tuvieron una periodicidad bienal (en sintonía con la LGDS, debido a que mandata que la pobreza categorizada por entidad federativa debe medirse como mínimo cada dos años) y acompañaron a la Encuesta Nacional de Ingresos y Gastos de los Hogares (ENIGH), de manera que una parte de la muestra la cubría la propia ENIGH (muestra ENIGH), captando información sobre ingreso y gasto; y otra el MCS (muestra MCS) captando solo información de ingreso. En el 2015 toda la muestra fue cubierta por el operativo del MCS, sin contar con el acompañamiento de la ENIGH. Esto pudo haber influido en que se observaran algunas diferencias en la información con respecto a los eventos anteriores.
Entre las diferencias que se observan en el MCS 2015 respecto a sus antecesores está un cambio en la tasa de crecimiento del total de hogares, que no es consistente con la tendencia observada desde el 2008.
Como se observa en la gráfica 2.1, del 2014 al 2015 la tasa de crecimiento promedio anual de los hogares según los MCS es de 3.3%, mientras que la que resulta de las proyecciones de población del CONAPO es de solo 1.9 por ciento. Este aumento en el crecimiento del número de hogares se debe, en parte, a que el tamaño del hogar reportado por el MCS 2015 es menor a lo proyectado y, como puede verse en la gráfica 2.2, muestra una ligera caída respecto a lo observado en el 2012 y 2014.

Como sucede en todas las encuestas sociodemográficas en las que la unidad de selección es la vivienda, un hogar en muestra representa a otros hogares con las mismas características socioeconómicas y demográficas. Así, los datos muestrales se expanden, con base en el inverso de su probabilidad de inclusión en una muestra, para referir no únicamente a la unidad muestral, sino a ésta más las que ella representa en la población de la que deriva dicha muestra. Sin embargo, debe considerarse que los factores de expansión de las encuestas sociodemográficas son ajustados con el fin de alcanzar el monto total de población proyectado por el CONAPO, independientemente del resultado en el número total de los hogares.
Considerando los factores naturales, es decir, los factores de expansión sin la corrección por la no respuesta ni la calibración por proyección de población, se observa que, en comparación con eventos previos, el tamaño promedio del hogar es menor en el MCS 2015 y, por lo tanto, el total de hogares en muestra arroja un menor registro de integrantes. Esto obliga a un ajuste adicional derivado del proceso de ajuste para alcanzar la cifra de población que indica la proyección del CONAPO; de lo contrario, el monto de población quedaría por debajo de lo proyectado para el año del levantamiento. El efecto final después del ajuste es que no solo aumenta el número de personas, sino el volumen de los hogares en los que habitan dichas personas, generando un efecto de mayor crecimiento. Esto significa que un hogar en muestra del MCS 2015 representa más hogares de los que representaría en los levantamientos previos que fueron acompañados con la ENIGH.
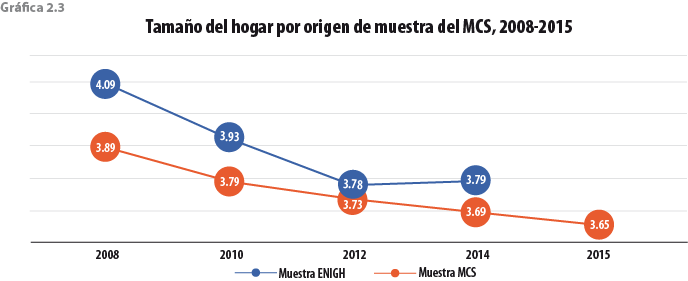
La baja tan pronunciada en el tamaño del hogar que arroja el MCS 2015 puede deberse a la omisión de personas, en términos del operativo de campo, debido a que en ocasiones el informante olvida reportarlos en la primera visita, sin embargo, se logra integrarlos en alguna de las visitas posteriores; esto es más viable para el levantamiento de la muestra ENIGH, dado que el hogar es visitado durante siete días consecutivos. En la muestra MCS es más factible que ese olvido persista, debido a que los cuestionarios pueden ser llenados en tan solo tres días y si en ese periodo no se consigue integrarlos, se pierde su registro. Esto lo podemos constatar en la gráfica 2.3, donde se observa que históricamente la muestra MCS reporta tamaños de hogar más bajos que la muestra ENIGH. Además, dado que el MCS 2015 solo tuvo muestra MCS, el tamaño del hogar sigue su tendencia a la baja. En cierta forma, se puede decir que el tamaño del hogar de la muestra ENIGH jala hacia arriba el tamaño del hogar de toda la muestra, permitiendo que no sea tan bajo. En el MCS 2015 esto no fue posible por la falta de muestra ENIGH.
 2.2 Métodos de imputación
2.2 Métodos de imputación
La mayoría de los sistemas de información requiere que le proporcionen datos (entrada o captura de datos) para su funcionamiento, los cuales necesitan ser validados.
En la entrada, los datos deben cubrir ciertas características para poder ser aceptados como correctos al momento de ser capturados. El proceso que permite verificar que esos datos cumplen con las características necesarias para ser aceptados se le llama validación. Para llevar a cabo este proceso, es necesario, primero, identificar el tipo de variable a tratar, ésta puede ser cualitativa (por ejemplo, el género y el nivel educativo de una persona) o cuantitativa (por ejemplo, la edad e ingreso de la persona); y segundo, construir reglas de validación, las cuales pueden involucrar una o más variables.
Por otro lado, no solo los sistemas de información requieren que la entrada de datos sea validada, por ejemplo, el INEGI cada año desarrolla un número importante de proyectos de naturaleza estadística, como censos y encuestas, en los cuales se implementa la validación en varias etapas: comenzando por la captación de los datos, siguiendo con la entrada de éstos a los sistemas de captura y finalizando con la validación de las bases de datos. A medida que el proceso avanza en las etapas, la validación se va haciendo más compleja, sobre todo porque se incrementa el número de variables involucradas en una regla de validación.
Aunado a lo anterior, al llevar a cabo los procesos de validación, pueden detectarse algunas variables con ausencia de información, lo cual puede darse por dos situaciones diferentes; en un primer caso, este escenario puede ser correcto: una persona en la variable edad reporta 3 años y el nivel de instrucción está vacío; en un segundo caso, esa ausencia puede deberse a una inconsistencia: una persona que reporta en edad 15 años y el nivel de instrucción está vacío (debería aparecer un código: por lo menos sin instrucción). En el segundo caso es necesario imputar (asignar) un dato a la variable nivel de instrucción para que pase el proceso de validación.
Al respecto veamos algunas definiciones y/o comentarios.
Palacios y González (2004) nos dice que: “…por imputación entenderemos la asignación de nuevos valores a aquellas variables, en uno o más registros, que necesitan ser corregidos para pasar el proceso de validación”.
De acuerdo con Schafer (2006): “…la imputación es la práctica de rellenar datos faltantes con valores probables, es una forma atractiva de analizar datos incompletos. Esto aparentemente resuelve el problema de análisis de datos incompletos. Sin embargo, un nuevo o poco escrupuloso método de imputación podría crear más problemas que los que resuelve, distorsionando estimaciones, errores estándar y pruebas de hipótesis”.
Según Juárez (2004): “…las imputaciones son extracciones de una distribución predictiva de los datos faltantes y requiere de un método para crear una distribución predictiva para la imputación basada en datos observados. La imputación es un método general y flexible para manejar problemas de datos faltantes”.
Dempster y Rubin (1983) consideran que: “La idea de la imputación es seductora y peligrosa. Seductora porque puede adormecer al usuario en un estado placentero de creer que los datos están completos después de todo y esto es peligroso porque junta situaciones en donde el problema es suficientemente menor que puede ser legítimamente manejado en esta forma y situaciones en donde estimadores estándares aplicados a los datos reales e imputados tienen sesgos substanciales”.
En pocas palabras, imputar es un procedimiento para asignar un valor a una variable con no respuesta para que el cuestionario pase el proceso de validación. Además, como señalan los autores mencionados, la imputación puede ser una buena solución al trabajar con datos incompletos, pero también tiene sus riesgos, ya que de no hacerse este procedimiento con el mayor de los cuidados, los datos finales pueden quedar muy sesgados y, por lo tanto, no mostrar la realidad que se pretende descubrir por medio de una encuesta.
Las imputaciones se pueden hacer de forma manual o automática. En el primer caso, el analista examina los datos y él mismo asigna un valor a la variable en cuestión. En el segundo caso, y de acuerdo con la UNECE (2000), las imputaciones automáticas se pueden clasificar en:
- Imputación determinística. Donde solo existe un valor correcto, por ejemplo, la falta de un total. Un valor como éste es determinado a partir de otros valores en el mismo cuestionario.
- Imputación basada en modelo. Usa una media, mediana, un modelo de regresión, etc., para imputar el valor.
- Imputación Deck. Se determina un cuestionario donador para suplir el valor faltante:
– Imputación Hot-Deck. El donador es encontrado en la misma encuesta. Pueden distinguirse dos variantes, el determinístico (vecino más cercano), en el que un único donador se identifica basado en una métrica y los valores se imputan de ese caso; y el aleatorio, en el cual el donante se selecciona aleatoriamente de un conjunto de posibles donadores.
-Imputación Cold-Deck. Con esta técnica, el donador se encuentra en la misma encuesta, pero de un evento previo. Las dos variantes del Hot-Deck pueden ser aplicadas en este caso. - Imputación Mixta. Utiliza una combinación de métodos. Primero se hace la imputación determinística y si ésta falla, se intenta una HotDeck y si aún sigue fallando lo hace con una imputación basada en modelo, y si de plano todas fallan, entonces se hace una manual.
- Sistemas expertos y redes neuronales. Se pueden desarrollar sistemas expertos o redes neuronales para imputar datos.
Entre los distintos métodos de imputación automática, el método Cold-Deck1 se considera una opción viable para el problema antes planteado debido a que no se trata de imputar valores ausentes en una variable cualitativa debido a una omisión en campo o captura, que pudiera rescatarse a partir de otros valores presentes en el mismo cuestionario, y para lo cual una imputación determinística resultaría suficiente. Tampoco se trata de predecir valores de una variable cuantitativa a partir del valor dado por la media, mediana, o por un modelo de regresión, y para lo cual la imputación basada en modelo sería la adecuada. En este caso se trata de corregir la omisión de individuos al interior de los hogares y, para ello, es posible aprovechar la información que previamente ha sido generada por el propio INEGI mediante los MCS anteriores. Así, a través de la técnica del Cold-Deck aleatorio es posible encontrar un donador en la misma encuesta, pero de un evento previo. A diferencia de la imputación Hot-Deck, donde el donador proviene del mismo evento, la técnica Cold-Deck permite ampliar la base de donadores con la finalidad de mejorar las precisiones estadísticas.
3. Metodología
3.1. Su aplicación
El procedimiento de imputación consistió de tres etapas: 1) determinar el volumen de población expandida a imputar, 2) definir las características sociodemográficas básicas del individuo a imputar y 3) el proceso de imputación como tal.
3.1.1 ¿Cuántos imputar?
Una vez definido el problema, surge la pregunta, ¿cuántos individuos imputar?
Se pueden tomar algunas encuestas del INEGI como punto de partida, de las cuales vale la pena revisar el dato que arrojan y sus características:
- Anclarse a la Encuesta Intercensal (EIC) 2015. Con un tamaño del hogar de 3.74 y una definición de hogar diferente a la de otras encuestas del mismo Instituto, provocando que los hogares no sean comparables debido a que la EIC reporta un hogar por vivienda, mientras que las demás pueden detectar más de uno.
- Basarse en la Encuesta Nacional de Ocupación y Empleo (ENOE). Con un tamaño del hogar de 3.79 (tercer trimestre del 2015) y tasas de variación irregulares. Esto es normal para la ENOE, ya que está diseñada para proporcionar información de la población de 15 años y más de edad sobre ocupación y empleo, como su nombre lo dice; por lo tanto, la información que se pueda obtener de los hogares es secundaria.
- La Encuesta Nacional de la Dinámica Demográfica (ENADID) 2014, con un tamaño del hogar de 3.71.
Al revisar estas encuestas no se dejó de lado el conocimiento de que el tamaño del hogar del MCS 2014 es de 3.73 y que el del MCS 2015 es menor que ése (3.65) y que parte del objetivo del ejercicio es acercarlo mas no dejarlo por arriba; por lo tanto, se descartó considerarlas para el ejercicio.
Otra opción consistía en tomar como referencia las proyecciones de población y hogares del CONAPO, específicamente las tasas de variación implícitas del tamaño del hogar. Que al final fue la vía que se tomó.
Entonces, se decidió que para ajustar demográficamente el MCS 2015, el tamaño del hogar de este evento debía ser menor que el del MCS 2014 para todas las entidades federativas, dada la tendencia a la baja que a través del tiempo muestran las proyecciones del CONAPO (ver tabla 3.1).
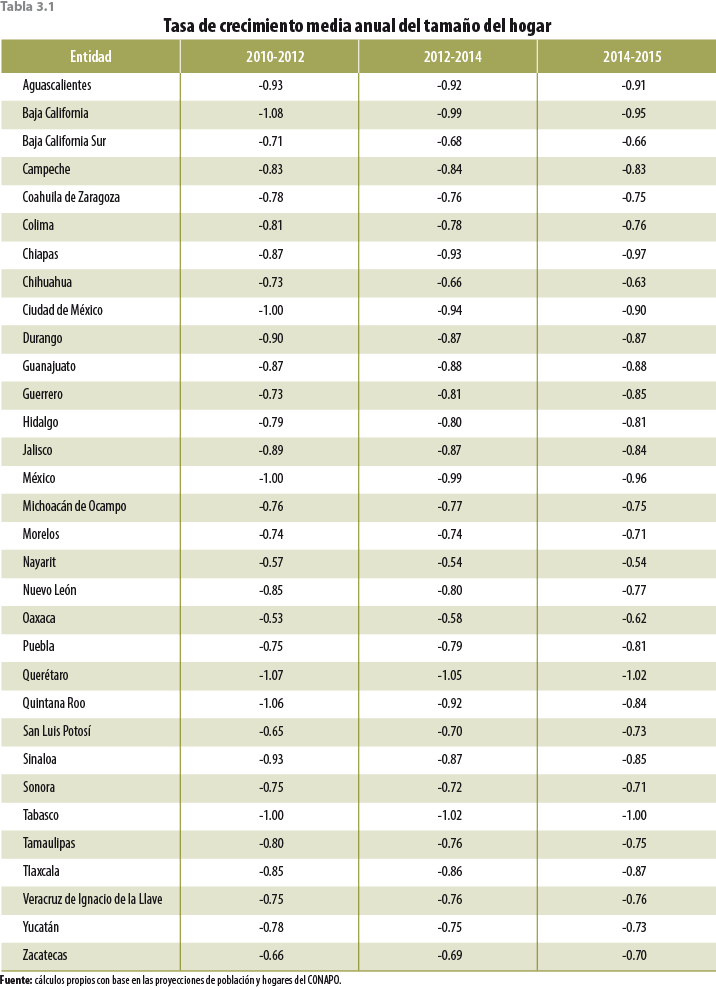
Con base en lo anterior, tomamos la tasa de variación implícita 2014-2015 del tamaño del hogar que reportan las proyecciones del CONAPO por entidad federativa (TChi , i = 1,…,32); así, por ejemplo, la tasa de variación de Aguascalientes es de -0.91% (TCh1 = -0.0091).
Y calculamos el tamaño del hogar esperado en la i-ésima entidad para el 2015 como sigue:
![]()
donde TamHOG14,i es el tamaño del hogar reportado por el MCS 2014.
Por ejemplo, para Aguascalientes que presenta TamHOG14,i= 3.83 se tiene que:
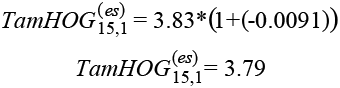
Con este dato, se calcula el total de hogares esperado para MCS 2015 en la i-ésima entidad:
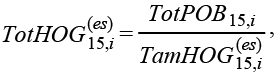
siendo TotPOB15,i la población total de la i-ésima entidad del MCS 2015.
Siguiendo con el ejemplo para Aguascalientes, la población reportada por el MCS 2015 fue TotPOB15,1 = 1 292 721, entonces, el total de hogares esperado es:
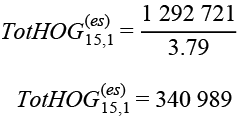
Sin embargo, con el total de hogares esperado y el tamaño del hogar del MCS 2015 para la mayoría de las entidades, no es posible llegar al total de población que reporta este evento, por lo que la población preliminar por entidad está dada por:
![]()
donde TamHog15,i representa el tamaño del hogar que arroja el MCS 2015 para la i-ésima entidad.
Luego, para Aguascalientes:
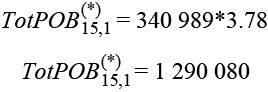
Por lo tanto, es necesario imputar población de forma expandida, que se obtiene por:
![]()
Siguiendo el caso de Aguascalientes, nos da:
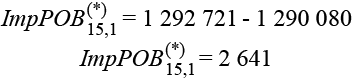
Esos 2 641 casos representan la cobertura de individuos que se deben imputar de forma expandida para Aguascalientes; cabe aclarar que en algunas entidades el resultado de este ajuste fue negativo; ante ello, se tomó la decisión de no hacer nada en esos casos (ver tabla 3.2).

3.1.2 ¿Qué y a quién imputar?
Una vez que se tiene el número de pobladores a imputar en cada entidad, ahora sigue determinar las características de los individuos donadores. Para ello, requerimos cuidar ciertos aspectos:
- La proporción de hombres y mujeres en las entidades federativas.
- La proporción de los grupos de edad (0 a 11, 12 a 64 y 65 y más), los tamaños de localidad y los estratos socioeconómicos tanto en hombres como en mujeres, por entidad federativa.
Al cuidar esas proporciones buscamos evitar que el proceso de imputación sesgue los resultados hacia una o varias categorías de esas variables, es decir, que al final del proceso haya más hombres que mujeres, por ejemplo.
Para obtener las proporciones, usamos información de la EIC y la ENOE, no con el fin de tratar de acercarse a su estructura poblacional (el MCS 2015 ya trae la propia y modificarla sería demasiado ostentoso) sino, como ya se dijo, para evitar el sesgo hacia alguna categoría.
Para decidir sobre las características que debe tener el donador, se usaron las proporciones ya mencionadas. En el caso del sexo se utilizaron las de hombres y mujeres por entidad federativa. Para grupos de edad, tamaño de localidad y estrato socioeconómico, se construyeron intervalos de decisión para cada categoría de manera que fuera de una longitud igual a la proporción observada ya sea en hombres o bien en mujeres (ver tablas 3.3 a 3.5 para el caso de Aguascalientes).
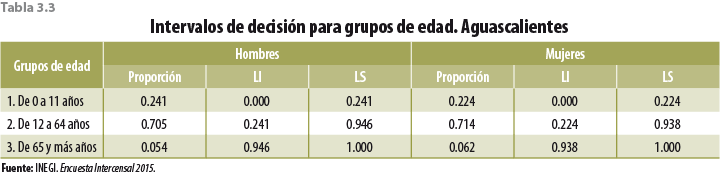
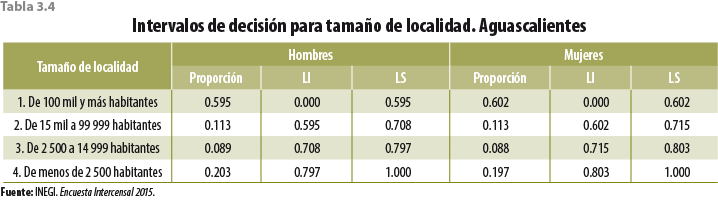

La segregación de sexo por las variables entidad federativa, grupos de edad, tamaño de localidad y estrato socioeconómico, realizada de forma independiente para obtener las proporciones, se hizo pensando que al hacer inferencia estadística a esos niveles se obtienen coeficientes de variación aceptables para un gran número de variables. Hacerlo de forma diluida, es decir, desagregando sexo dentro de grupos de edad, estrato socioeconómico, tamaño de localidad y entidad federativa complicaría el procedimiento (dada la alta posibilidad de no encontrar donadores), además de que la inferencia estadística a esos niveles de desagregación arroja coeficientes de variación no satisfactorios.
El proceso de asignación de características se lleva a cabo entidad por entidad, generando números aleatorios de la distribución uniforme, siendo de la siguiente forma:
- Para determinar el sexo, se genera un primer número aleatorio, si este es menor o igual a la proporción de hombres, se asigna un hombre, de lo contrario, se asigna una mujer.
- Ya que se tiene el sexo del individuo, se genera un segundo número aleatorio para asignarle el grupo de edad condicionado al sexo determinado con anterioridad. Para decidir sobre éste, se verifica en qué intervalo de decisión se incluye.
- Para saber qué tamaño de localidad y estrato socioeconómico es asignado, se generan un tercer y cuarto números aleatorios, y se revisa el intervalo de decisión en el que se incluyen, condicionado también al sexo.
3.1.3 Proceso de imputación
El proceso de imputación se hace también entidad por entidad.
- Para seleccionar a los hogares receptores de individuos, se usa la técnica Permanent Random Numbers (PRN). Ésta consiste en asignar un número aleatorio (de la distribución uniforme) a cada hogar y después ordenarlos descendentemente por ese aleatorio.
- Una vez ordenados los hogares por el número aleatorio, se busca el primer hogar que cumpla con las condiciones de mismo tamaño de localidad y mismo estrato socioeconómico como los ya designados.
- Se asigna el individuo a ese hogar y se acumula su factor de expansión, luego el siguiente y acumulando su factor de expansión y así hasta que el factor acumulado supere la cobertura de la entidad, como se muestran en la tabla 3.1.
Una vez que se determinó lo que ha de imputarse y se seleccionaron los receptores, se procede al proceso de imputación de valores para el resto de variables aún no determinadas.
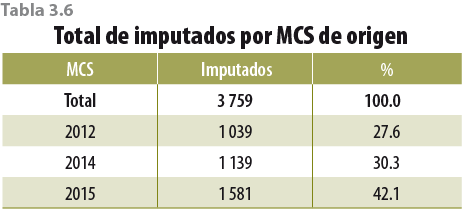
Para asegurarnos de encontrar posibles donadores, se construyó un agregado (pool) de pobladores de los MCS 2012 a 2015 con el fin de tener un conjunto de individuos mucho más grande de dónde obtener dichos donadores. En la tabla 3.6 se presentan el total de imputados y su origen.
El método de imputación usado fue Cold-Deck aleatorio, considerando las siguientes variables de empate para encontrar posibles donadores:
- Entidad federativa.
- Tamaño de localidad.
- Estrato socioeconómico.
- Clase de hogar (nuclear, ampliado y compuesto).
- Sexo, edad y nivel educativo del jefe del hogar.
- Sexo y grupo de edad del individuo a imputar.
A pesar de que se pudo haber elegido un conjunto más amplio de variables, no se hizo, puesto que con dicha decisión se corría el riesgo de que en un gran número de casos no encontraran posibles donadores.
Es importante mencionar que aunque la clase de hogar se incluyó como variable de empate, se determinó no modificarla. Para ello, se filtraron los parentescos que pueden ser parte de cada clase; por ejemplo, para hogar nuclear solo se buscaron donadores cuyo parentesco fuera hija o hijo, para hogares ampliados solo se buscaron a hijas o hijos y otros parientes, y para compuestos se buscó a hijas o hijos, otros parientes y no parientes. En la tabla 3.7 se puede observar el total de imputados por la clase de hogar y parentesco.

Además, para los parentescos se aplicaron ciertos filtros:
- Si el donador era hija o hijo, se cuidó que la edad de la jefa o del jefe del hogar receptor fuera 13 o más años mayor a dicho donador, con el fin de evitar imputar un hijo mayor que el jefe.
- Si el donador era hija o hijo y el hogar receptor era encabezado por una mujer, se buscó que la diferencia máxima de edades entre la jefa o el jefe y el donador fuera de 45 años, para evitar imputar hijas o hijos menores de 12 años a jefas de hogar de la tercera edad.
- Si el donador era nieta o nieto, bisnieta o bisnieto o bien tataranieta o tataranieto, se cuidó que la edad de la jefa o el jefe del hogar receptor fuera 26, 39 y 52 años mayor que aquéllos (como mínimo), respectivamente.
- Si el donador era abuela o abuelo, bisabuela o bisabuelo o bien tatarabuela o tatarabuelo, se cuidó que la edad del jefe del hogar receptor fuera 26, 39 y 52 años menor que aquéllos (como mínimo), respectivamente.
Además, cabe aclarar que solo se donó la información sociodemográfica del individuo, excluyendo toda aquella relacionada con ingresos, gastos y trabajos. Así que, cuando se imputó a un individuo cuyo donador estaba clasificado como población no económicamente activa (PNEA) o buscador de trabajo, se le respetó la categoría. Sin embargo, cuando el donador era una persona con trabajo, se cambió la condición de actividad a PNEA o buscador de trabajo del individuo agregado. Lo anterior en el entendido de no incrementar el número de trabajadores.
Los siguientes puntos enuncian la forma en que quedaron clasificados aquellos registros en los que sus donadores eran parte de la población económicamente activa (PEA):
- Como estudiante si asistía a la escuela.
- Dedicado a quehaceres domésticos si era menor de 15 años de edad y no asistía a la escuela.
- Buscador de trabajo si era hombre de 15 años y más y no asistía a la escuela.
- 46% de las mujeres se clasificaron como dedicadas a quehaceres domésticos si eran de 15 años y más y no asistía a la escuela; las restantes (44%) se catalogaron como buscadoras de trabajo (en virtud de los porcentajes de mujeres de 15 años y más que se clasifican como PNEA y PEA2 ).
Debido a que son pocas las características de empate entre la persona que se busca y los posibles donadores, al ir por estos últimos se pueden encontrar más de uno. Si esto ocurre, se vuelve a usar la técnica PRN para elegir solo uno.
Una vez concluido el proceso de imputación, dado que hay más pobladores, se reajustaron los factores de expansión (ajuste de razón por entidad y tamaño de localidad) usando como base los factores de expansión del propio MCS 2015 (como fueron publicados) para que el total de la población expandida fuera congruente con las proyecciones del CONAPO para el 2015. En general, ello significa que los factores de expansión no tienen que ser tan grandes como los originales y, por ende, se obtienen menos hogares.
3.2. Nota técnica
3.2.1 Software usado
Visual FoxPro 9.0 de Microsoft fue el software usado para llevar a cabo el procedimiento de imputación. Esta pieza de software es un lenguaje de programación procedural y orientado a objetos que incluye un Sistema Gestor de Bases de Datos (DBMS, por sus siglas en inglés).
Para llevar a cabo el trabajo, se hizo uso tanto del lenguaje de programación como del SQL que este software incluye.
3.2.2 Fuentes utilizadas
La primera fuente de información usada fueron las proyecciones del CONAPO con el fin de obtener las variaciones 2014-2015 del tamaño del hogar. Una segunda fue la Encuesta Intercensal 2015, de la cual se consiguieron las proporciones de hombres y mujeres por entidad federativa, las proporciones de hombres por grupos de edad y tamaño de localidad, así como las proporciones de mujeres por grupos de edad y tamaño de localidad, en cada entidad federativa. Otra más fue la Encuesta Nacional de Ocupación y Empleo, de la que se obtuvieron las proporciones de hombres por estrato socioeconómico y mujeres por los mismos estratos en cada entidad federativa.
Ahora bien, para incrementar las posibilidades de encontrar donadores para todos los casos a imputar, se construyó un pool de pobladores con los MCS 2012 a 2015, donde se incluyeron todas las variables sociodemográficas (solo la tabla Población de la base de datos).
Entonces, enlistando las fuentes, serían:
- INEGI. Módulo de Condiciones Socioeconómicas 2012.
- INEGI. Módulo de Condiciones Socioeconómicas 2014.
- INEGI. Módulo de Condiciones Socioeconómicas 2015.
- INEGI. Encuesta Intercensal 2015.
- INEGI. Encuesta de Ocupación y Empleo. Tercer trimestre del 2015.
- CONAPO. Proyecciones de población nacional y entidades federativas, 2010- 2030.
- CONAPO. Proyecciones de los hogares en México y las entidades federativas, 2010-2030.
4. Resultados
4.1 Resultados en el ámbito nacional, por entidad federativa y por decil con la nueva base del MCS 2015
4.2 Comparación de los resultados con los publicados para el MCS 2015 y ENIGH-MCS 2010, 2012 y 2014. A nivel nacional, por entidad federativa y por decil



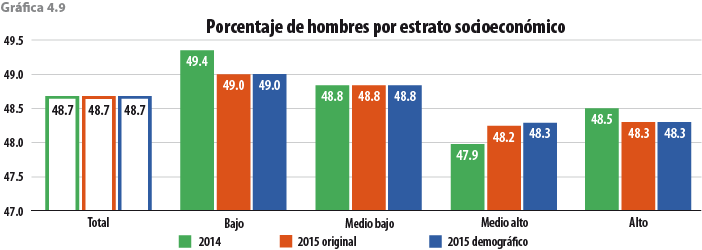
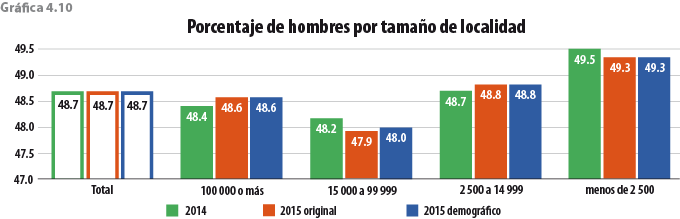

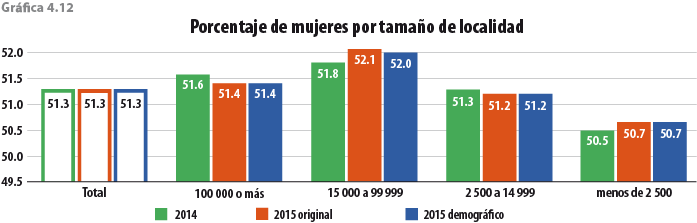
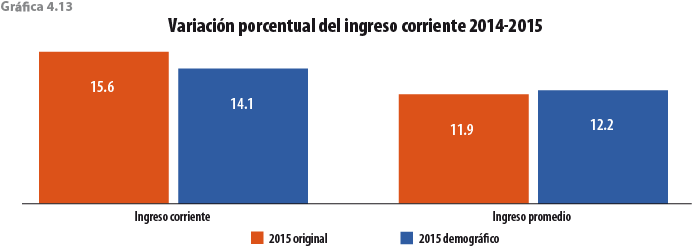



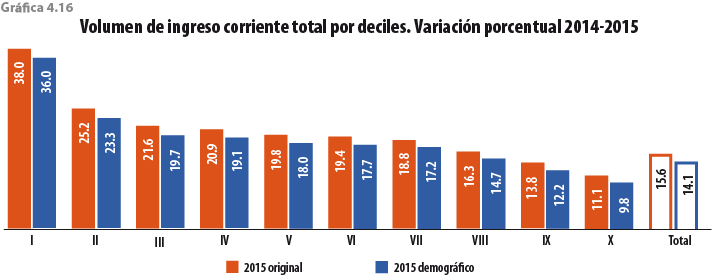

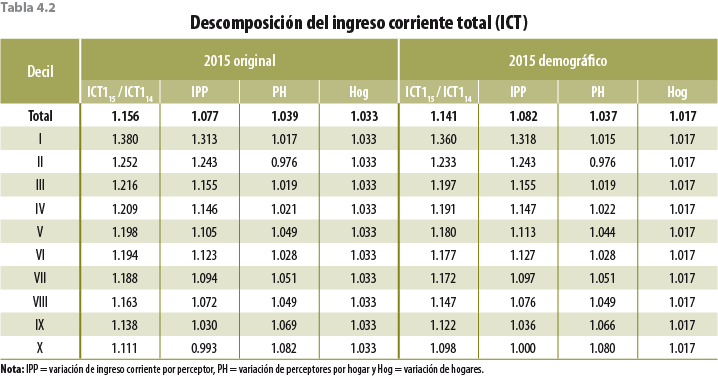


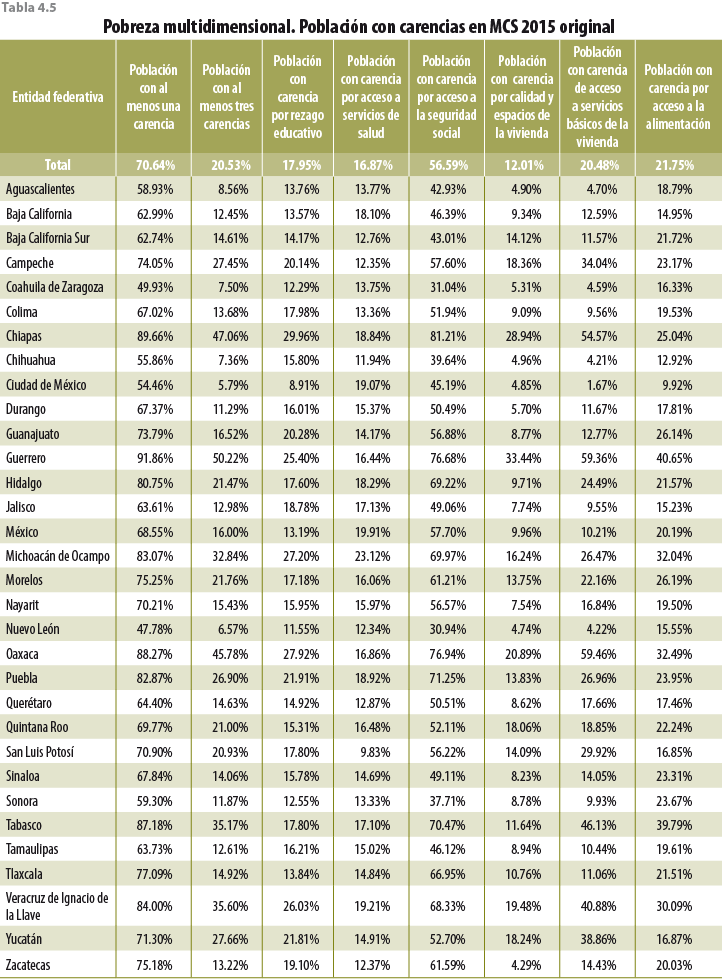
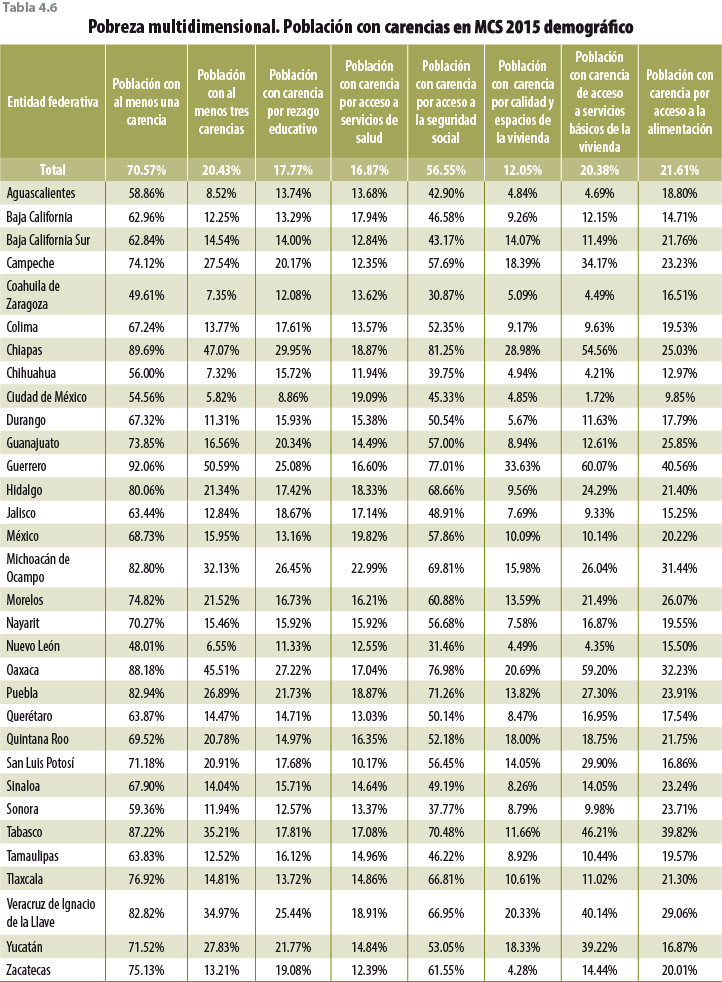
5. Validación y evaluación de la metodología
Aunque el ajuste demográfico no tiene gran impacto en la disminución del ingreso y aumento de la pobreza del MCS 2015, sí elimina el efecto que el problema demográfico pudiera tener en éstos, es decir, este ejercicio elimina los posibles efectos que el comportamiento demográfico podría representar para que el MCS 2015 arrojara ingresos más altos que lo que se venían captando en los eventos anteriores. Así, pone el piso base para que se realicen ejercicios de alineación a los eventos anteriores.
Sin duda, los métodos de imputación Deck arrojan resultados satisfactorios cuando existe un conjunto muy grande de posibles donadores como en este ejercicio. Sin embargo, cuando el conjunto de posibles donadores es pequeño, para un gran número de casos existe la posibilidad de que se encuentren el o los mismos donadores, eliminando poco a poco la variabilidad en las observaciones y como consecuencia compactar las varianzas.
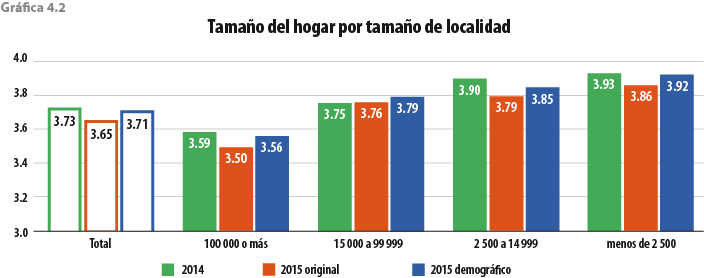
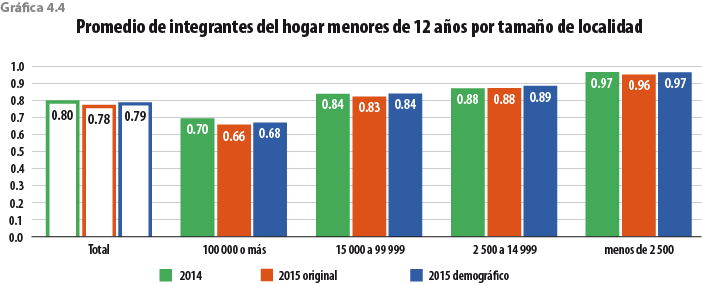
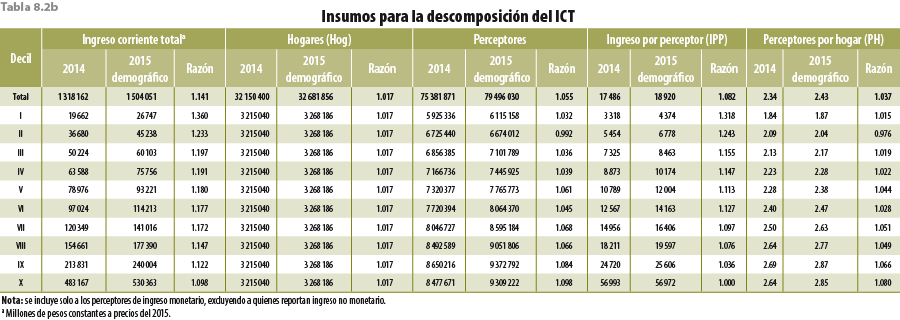
Ahora bien, para este ejercicio en específico, los resultados fueron muy satisfactorios. Si observamos la gráfica 5.1, notamos que se cumple con el objetivo de incrementar el tamaño del hogar del MCS 2015, al pasar de 3.65 a 3.71. Además, el total de hogares lo deja en 32 681 856 y no los 33 218 037 del MCS 2015 original (536 181 hogares menos), dejando la tasa de crecimiento de éstos entre el 2014 y 2015 en 1.65, muy por debajo del 3.3 del original.

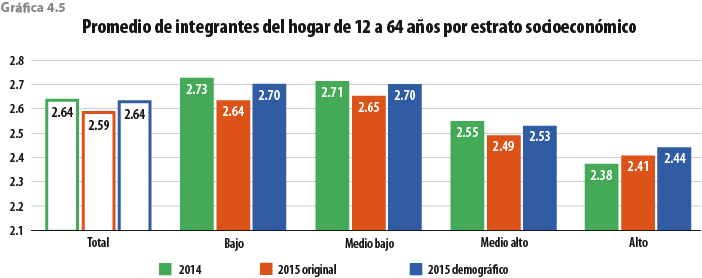
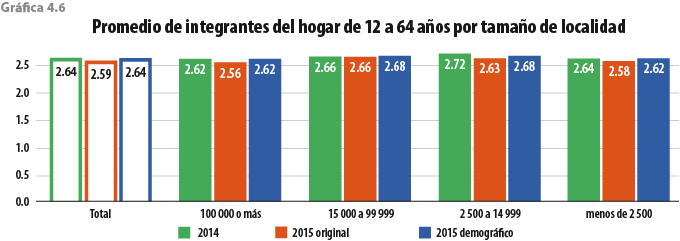
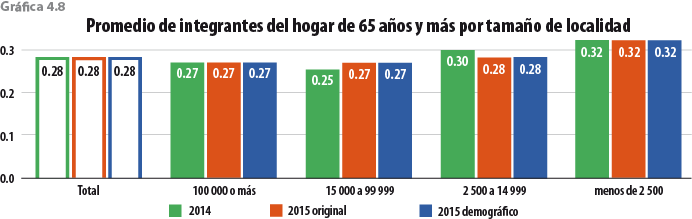
Por otro lado, en la gráfica 5.2 se presenta la descomposición del tamaño del hogar en grandes grupos de edad, pudiendo observar que el ejercicio se acerca a la tendencia histórica del MCS, sobre todo en el grupo de 12 a 64 años, que es donde se presenta el desajuste del MCS 2015 original. También se comporta mejor que la EIC 2015 y que un ejercicio de posestratificación del MCS 2015 con Stata (teniendo como base las variables total de integrantes del hogar, edad y sexo de la jefa o del jefe del hogar que reportó la EIC 2015), ya que estos dos últimos rejuvenecen la población.

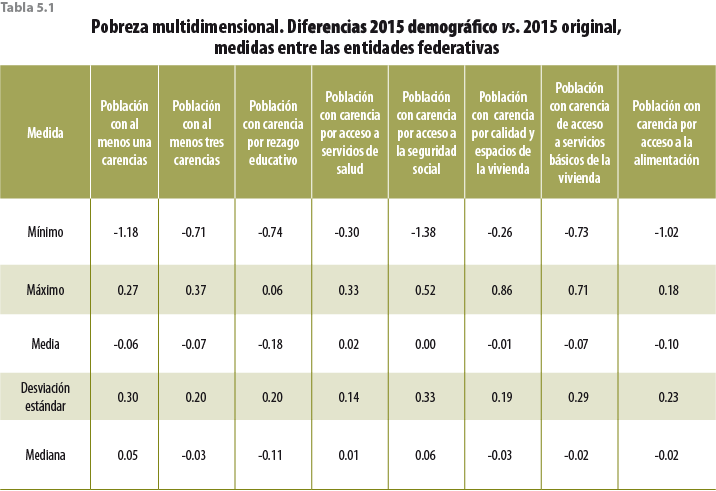
Así como en el ingreso, en las carencias no hay grandes efectos de que preocuparse. Como se observa en el cuadro 5.3, las diferencias en las entidades federativas entre el MCS 2015 original y el MCS 2015 demográfico van desde -1.38 hasta 0.86 por ciento. Aunque estas diferencias mínimas no necesariamente pueden ser aplicables a todas las variables, para conocer los efectos a profundidad del ajuste demográfico es necesario hacer un análisis sobre aquellas que se puedan considerar las más importantes del MCS 2015.
6. Conclusión y comentarios finales
Los resultados del ejercicio logran el objetivo de incrementar el tamaño del hogar de acuerdo con las tasas de variación implícitas calculadas a partir de las proyecciones de hogares y población del CONAPO y como consecuencia disminuir el total de hogares que reportó el MCS 2015.
Los efectos en el ingreso y la pobreza son marginales, ya que logra disminuir muy poco el monto del ingreso corriente y aumentar, también muy poco, al promedio de ingreso por hogar (debido a la disminución de los hogares) y la pobreza, esto respecto al original.
Las restricciones en cuanto a sexo, edad, tamaño de localidad y estrato socioeconómico, aunado a la aleatoriedad del ejercicio, logran una distribución consistente de la población para esas variables.
Probablemente existan otros métodos de imputación más efectivos que los Deck, pero es un hecho que éstos son los más simples y fáciles de implementar, y sus resultados se pueden considerar satisfactorios. Sin embargo, es posible explorar en la literatura otros métodos más efectivos y compararlos con éstos, en estudios futuros.
Referencias
Dempster, A. P. y D. B. Rubin. Incomplete data in sample surveys. Academic Press, New York, NY, pp.3-10, 1983.
Juárez Alonso, Carlos Alberto. Fusión de datos: imputación y validación. Tesis doctoral, Universidad Politécnica de Cataluña, 2004.
Kim, J. K. y W. Fuller. “Fractional hot deck imputation”, en: Biometrika. 91(3):559-578, 2004.
Palacios Ostria, Margot Alejandra y Edgar Javier González Liceaga. Metodología de Fellegi y Holt: validación e imputación de datos. Tesis profesional, UNAM, 2004.
Schafer, J. L. The multiple imputation FAQ page. (DE) consultada el 9 de enero de 2017 en http://www.stat.ufl.edu/~athienit/STA6167/ Missing%20Data/MI_FAQ.pdf
United Nations Statistical Commission and Economic Commission for Europe. Glossary of terms on statistical data editing, UNECE, 2000. (DE) consultada el 9 de enero de 2017 en:
bit.ly/4cZYYgZ
Anexos

 _____
_____
1 Kim y Fuller (2004) mencionan que la imputación Hot-Deck aleatoria preserva las propiedades distributivas del conjunto de datos imputado, además de introducir variabilidad al seleccionar aleatoriamente al donante. Esto es aplicable al método ColdDeckaleatorio.
2 INEGI. Encuesta Nacional de Ocupación y Empleo. Tercer trimestre del 2015.

Potenciales de aptitud del territorio y riesgo mayor de reproducción del Pequeño Escarabajo de la Colmena, Aethina tumida Murray (Coleoptera, Nitidulidae) en México

Suelo agrícola en México: retrospección y prospectiva para la seguridad alimentaria
