Análisis de eficiencia en los servicios del agua en México con datos de los Censos Económicos
Analysis of Efficiency of Water Services in Mexico Using Data from the Economic Censuses
Ismael Aguilar Benítez
El Colegio de la Frontera Norte, iaguilar@colef.mx
Vol. 11, Núm. 3 – Epub Análisis de eficiencia…– Epub

|
En este trabajo se analiza la eficiencia técnica de los organismos de captación, tratamiento y suministro de agua en México utilizando datos generados por los Censos Económicos. Para ello, se comparan cinco estimadores obtenidos mediante la aplicación de técnicas basadas en el concepto de fronteras de eficiencia. Las principales aportaciones de esta investigación son que se utiliza por primera vez una base de datos económicos censales para estimar la eficiencia técnica de los servicios del agua en nuestro país, que se realiza un análisis comparativo de la eficacia de estimadores de fronteras de eficiencia en un contexto de fuerte presencia de valores atípicos y errores en los datos y que los resultados permiten identificar mecanismos para el diseño de políticas públicas específicas para fortalecer estos servicios. En general, se recomienda una efectiva regulación y mayor profesionalización en los servicios del agua. Palabras clave: eficiencia; organismos de captación, tratamiento y suministro de agua; censos económicos; México.
|
The efficiency of water services in Mexico is analyzed using data from the Economic Censuses. We compare estimates generated with five techniques based on the concept of efficiency frontier. The three main contributions of this work are: one, a census database is used for the first time to estimate the technical efficiency of water services in Mexico; two, a comparative analysis of the effectiveness of the estimators is performed in a context of strong presence of outliers and errors in the data. Three, the results allow identifying mechanisms for the design of policy recommendations for the sector; In general, it is recommended an effective regulation and professionalization of the water services. Key words: technical efficiency; water utilities; economic census; Mexico. |
Recibido: 18 de agosto de 2020.
Aceptado: 28 de agosto de 2020..
Introducción
La evaluación de la eficiencia de las organizaciones que proveen los servicios de agua potable, drenaje y saneamiento proporciona información relevante para los administradores de esos servicios y el diseño de políticas públicas (Picazzo-Tadeo et al., 2009).[1] Utilizar de manera eficiente los distintos insumos para su provisión es una condición necesaria para que la población tenga acceso a ellos, con características adecuadas de cantidad, calidad y continuidad. Su disponibilidad es esencial para proteger el derecho humano al vital líquido, al saneamiento y a la salud, como lo ha mostrado la reciente contingencia sanitaria por el COVID-19, durante la cual ha sido indispensable tener agua para la higiene personal y de la vivienda.
No obstante su importancia, quienes ofrecen el servicio tienen escasos incentivos para mejorar su eficiencia. En la práctica, en México y en otros países, los servicios de agua y saneamiento operan como monopolios debido a características económicas especiales, por lo que en cada ciudad o población solo hay un proveedor (Aguilar-Benítez, 2011). Por otro lado, la gran mayoría de estas compañías operan bajo la administración del sector público y dependen financieramente del subsidio. Ambas características (monopolio y dependencia de fondos públicos) ocasionan, en parte, que esas organizaciones tengan pocos estímulos para ser eficientes en el uso de sus recursos y, aún menos, para brindar atención de calidad.
En este trabajo nos enfocamos al análisis de la eficiencia técnica de los organismos que proveen de servicios del agua a las localidades de México, la cual puede entenderse como la mejor combinación de insumos necesarios para generar una determinada cantidad de producto.[2]
Aunque cada uno de estos utiliza insumos semejantes (p. e. agua, mano de obra, cloro y otros materiales para potabilización, energía eléctrica y redes para distribución, entre otros), la forma en la que se combinan difiere por múltiples razones, como la fuente principal de agua, su calidad, condicionantes topográficas en el área que cubren, así como su contexto demográfico, económico y organizacional, por mencionar algunos. La presencia de múltiples insumos y los resultados que generan (ingresos por tarifas, conexiones con servicio, volúmenes de agua potabilizada, recolección de aguas residuales, volumen de aguas residuales tratadas), así como una relación compleja entre ellos, son características que hacen necesaria la aplicación de métodos específicos para la estimación de eficiencia.
En esta investigación se analiza la eficiencia de proveedores de servicios del agua utilizando los datos generados por el cuestionario para los organismos que realizan la actividad de captación, tratamiento y suministro de agua (OCTSA),[3] el cual forma parte de los Censos Económicos (CE) 2014 en México.[4] Como único antecedente de una obra similar se registra un trabajo en el que se analizó el efecto de la descentralización en la eficiencia de una muestra de 110 organismos operadores (Anwandter y Ozuna, 2002).
Las principales aportaciones son tres: 1) desde un punto de vista empírico, se utiliza por primera vez una base de datos censales para estimar la eficiencia técnica de los OCTSA en México y se muestra su potencial para el análisis de esta actividad; 2) desde una perspectiva metodológica, este trabajo busca contribuir al análisis comparativo de la eficacia de los estimadores analizados para el estudio de la eficiencia técnica en un contexto de fuerte presencia de valores atípicos y errores en los datos; y 3) los resultados de este ejercicio permiten identificar elementos para el diseño de políticas públicas para mejorar el desempeño de los servicios del agua en México.
Es importante mencionar que aquí se restringe el análisis de la eficiencia técnica a la información disponible sobre un grupo de variables (insumos y producto) y no incluye lo relacionado con la calidad en el servicio y el agua o la continuidad de los servicios, aspectos importantes para cuyo análisis se requiere información que no se encuentra disponible en la base de datos utilizada.
El escrito se organiza como sigue: la siguiente sección presenta las características de los OCTSA en México derivadas del cuestionario ya mencionado; en la segunda se caracteriza el enfoque de fronteras de eficiencia y se describen los estimadores que se aplicaron; en la tercera, se muestran los principales resultados de la estimación, aplicando los cinco estimadores con respecto a su eficacia para reducir el sesgo generado por una alta presencia de valores atípicos; y en la sección final se presentan las conclusiones.
Características de los OCTSA en México, CE 2014
El número total de organismos censados en México en 2014 fue de 2 688. Un OCTSA puede proveer de servicios, en muchos casos, solo a la cabecera municipal, aunque también puede abastecer a varios municipios o, incluso, a toda la entidad (p. e. Servicios de Agua y Drenaje de Monterrey abastece a todo el estado de Nuevo León). Las formas de organización son diversas, principalmente: organismos operadores, sistemas de agua, juntas locales, comités municipales y concesionarias de agua particulares. Del total, 2 401 OCTSA (90 %) se clasifican como servicios del sector público; 257 (9 %) se registran como asociaciones civiles y solo 30 (1 %) operan como sociedades mercantiles con fines de lucro o sociedad cooperativa; de la totalidad, 1 394 proveen servicios a poblaciones exclusivamente urbanas y 1 294, a centros tanto urbanos como rurales.
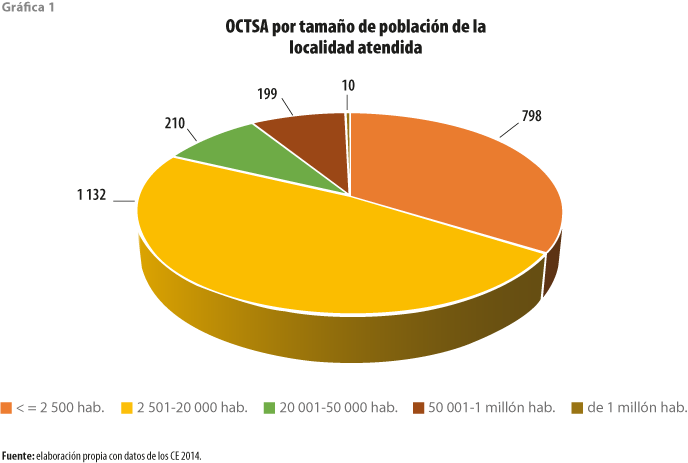
En México, 33 % de los OCTSA provee de servicios a localidades menores a 2 500 habitantes, mientras que el tamaño más frecuente se encuentra en el rango de 2 501 a 20 mil (48 %) y solo 10 de la base de datos final para este trabajo abastecen a asentamientos urbanos con más de 1 millón de habitantes (ver gráfica 1). Los OCTSA emplearon, en 2013, a 122 798 personas; 96 % de este personal dependía en forma directa del organismo y el resto era subcontratado. Los organismos no necesariamente funcionan en un tamaño óptimo, pueden ser muy pequeños (con algunos cuantos empleados, para un número reducido de conexiones) o crecer más allá de su tamaño recomendable de personal.
La cantidad total de agua captada por los OCTSA fue de 12 400.6 millones de metros cúbicos anuales, considerando el volumen de extracción de fuentes superficiales (27 %), del subsuelo (61 %) y del resto que proviene de compras de agua en bloque (varios OCTSA requieren realizar esta acción para complementar el volumen del líquido que necesitan debido, sobre todo, al agotamiento o sobreexplotación de fuentes locales). De acuerdo con los volúmenes reportados, solo la mitad (51 %) del agua suministrada se cobra.
Para ofrecer servicios del agua en México, se reportaron gastos por consumo de bienes y servicios por un monto total de 24 935.3 millones de pesos. Los principales conceptos que generaron esos gastos son: energía eléctrica (39.5 %); suministro de agua en bloque (16.1 %); reparaciones y refacciones para mantenimiento (9.8 %); compra de agentes físico-químicos, reactivos y otros materiales para la distribución de agua (7.6 %); y combustibles, lubricantes y energéticos (5.4 %); el resto (21.6 %) se destinó a otros pagos, como: publicidad, papelería, servicios de comunicación y profesionales, primas de seguros, entre otros.
Por suministro de bienes y servicios, los OCTSA obtuvieron un total de 47 561.2 millones de pesos, ingresos que se generaron, sobre todo, por: suministro de agua (69.3 %), derechos de conexión y alcantarillado (11.8 %), ingreso por ejercicios anteriores (9.2 %), venta de agua tratada (2.1 %) y otros conceptos (7.6 %). En este último rubro se incluyen la venta de lodos e ingresos tanto por publicidad como por la distribución de agua con pipas. De los proveedores de servicios del agua, 35 % reportó ingresos por suministro de bienes y servicios menores a sus gastos.
Como se ha descrito, en México se registra un gran número de OCTSA con una diversidad de formas de organización y tamaños de localidades a las que proveen servicios. Dos indicadores de las debilidades en su operación es que, en promedio, solo la mitad del agua suministrada se cobra y la tercera parte de estos operadores no recuperan sus gastos por consumo de bienes y servicios.
Noción de frontera de eficiencia y técnicas no paramétricas
Para el análisis empírico de la eficiencia técnica, se han propuesto en la literatura especializada dos enfoques: uno es el conocido como paramétrico y el otro, el no paramétrico. La diferencia principal entre ellos es que, mientras que en los métodos que utilizan el primero se requiere especificar una función de producción con parámetros que la caracterizan, en los que emplean el segundo no se necesita determinarla. En los primeros, la especificación de una función de producción que se analiza con técnicas econométricas es muy relevante para obtener resultados confiables; en contraste, una ventaja de los no paramétricos es que no es necesario asumir o establecer una que defina la relación entre insumos y productos o resultados, esto es, no se especifica la forma funcional de la función de producción.
Debido a que, de manera usual, no existe una única combinación que genere los mejores resultados, una opción para evaluar la eficiencia de una unidad es compararla dentro de un grupo o muestra. Los métodos no paramétricos responden a esa necesidad empírica de evaluar la eficiencia como una noción relativa a la mejor práctica observada en un conjunto de unidades de referencia o grupo de comparación (Daraio y Simar, 2007).
La base de la cual parte la inferencia no paramétrica es usar un conjunto de observaciones para evaluar la eficiencia de cada unidad (empresa, organización o unidad de decisión) con respecto a la del conjunto de datos. La eficiencia técnica se obtiene al comparar el valor observado de cada unidad con el óptimo que se determina por una frontera de producción estimada. La frontera de producción puede entenderse intuitivamente como la unión de las diferentes combinaciones que optimizan los insumos necesarios para generar una cantidad de producto; por ejemplo, en el caso simple de un producto o resultado (Y) generado con dos factores o insumos (x1, x2) en nueve diferentes organizaciones (A, B, … I) se registran las distintas combinaciones que cada una utiliza para generar la unidad de producto.

Al graficar esas combinaciones, registrando como coordenadas los valores de los insumos x1 y x2 en los ejes horizontal y vertical de un cuadrante —esto es, las cantidades que cada organización necesita de cada insumo para generar una Y— se pueden identificar los puntos ilustrados (A…I) en la gráfica 2. Uniendo los tres puntos (E, D y C), que representan las diferentes combinaciones con los menores valores de insumos, se construye la frontera de eficiencia. En el punto E, la línea vertical proyecta la frontera de eficiencia marcando el límite para el insumo x2, mientras que la línea horizontal proyectada en el punto C hace lo propio para el caso del insumo x1.
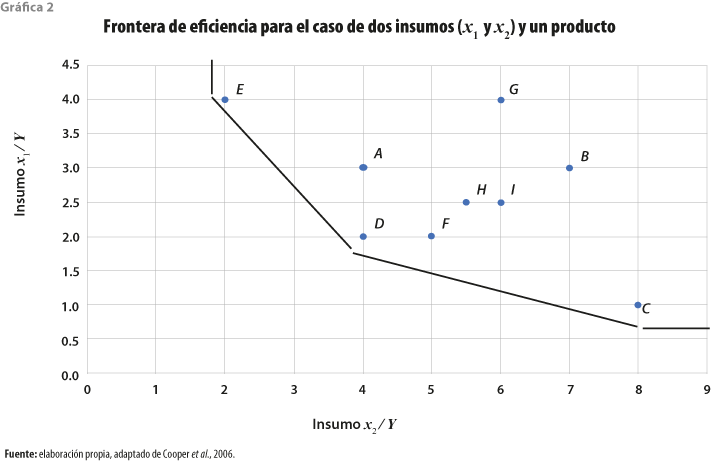
Como puede observarse en la gráfica 2, la curva generada envuelve las distintas combinaciones observadas; de este resultado gráfico se deriva el nombre de una de las técnicas más usuales no paramétricas: el análisis envolvente de datos (DEA, por sus siglas en inglés), que se describirá más adelante. En este ejemplo, los puntos (combinaciones de insumos) que se encuentran por encima de la frontera de eficiencia son ineficientes, pues para generar una unidad de producto requieren de una mayor cantidad de, al menos, un insumo comparado con las tres organizaciones eficientes. Como puede intuirse con esta gráfica, los puntos G y B son los más alejados de la curva y, por lo tanto, los más ineficientes.
A partir de esa noción de frontera se pueden explicar los distintos modelos utilizados para el análisis no paramétrico de la misma, el cual requiere dos especificaciones iniciales en sus modelos. La primera de ellas es la orientación de la eficiencia, que puede ser hacia los insumos, lo cual implica que las unidades tomadoras de decisiones (DMU, por sus siglas en inglés) buscan, dado un nivel fijo de producto(s), la máxima reducción proporcional en la combinación de insumos. Este es el caso del ejemplo simple ilustrado en la gráfica 2, en la que se define la frontera de eficiencia con las combinaciones de menores cantidades de insumos para generar una unidad de producto. En el caso contrario (la eficiencia orientada hacia los productos), las DMU buscan, dado el nivel de insumos, el máximo incremento proporcional de los productos, permaneciendo dentro de la frontera de posibilidades de producción. Para el caso de los servicios del agua, es razonable asumir que, dado un contexto de limitada disposición de insumos (agua, recursos financieros para infraestructura hídrica, energía eléctrica y mano de obra, entre los principales), la orientación pertinente es hacia los insumos.
Una segunda especificación necesaria para la aplicación de modelos no paramétricos es el tipo de rendimientos de escala que se asume: constantes cuando, para generar un incremento (reducción) en la cantidad de producto, se requiere un incremento (decremento) proporcional de cada insumo necesario; o variables, cuando al incrementar (reducir) la cantidad utilizada de los factores, la cifra obtenida del producto se incrementa (reduce) en una proporción distinta a la de los insumos. En el caso de los servicios del agua, no existe un consenso en la literatura sobre este supuesto, por lo que en este trabajo se realiza una prueba en la base de datos para definir la especificación de rendimientos de escala del modelo.
Para evaluar la eficiencia técnica de los servicios del agua en México, se comparan estimaciones que resultan de la aplicación de cinco técnicas no paramétricas conocidas como: 1) análisis envolvente de datos, 2) libre disponibilidad de factores (FDH, por sus siglas en inglés), 3) de orden m, 4) de orden alfa (orden α) y 5) corregido por sesgo (BC, por sus siglas en inglés), las cuales se describen enseguida.
1) DEA
El primer estimador no paramétrico de fronteras de eficiencia instrumentado para el análisis empírico de los OCTSA es el que resulta del análisis envolvente de datos. Esta técnica compara las DMU, considerando todos los insumos utilizados y los productos generados (Cooper et al., 2011). De manera gráfica, el conjunto de soluciones posibles genera una envolvente de todas las observaciones (como se ilustró en la gráfica 2 con un caso simple), de ahí el nombre de la técnica: DEA. La eficiencia de una DMU, definida por Farell en 1957, se evalúa con la distancia radial del nivel en el que opera a su punto correspondiente en la frontera. DEA utiliza programación matemática y fue instrumentada para su aplicación empírica por Charnes, Cooper y Rhodes (1978). El tratamiento de los rendimientos variables a escala en el modelo DEA (conocido como BCC por haber sido desarrollado por Banker, Charnes y Cooper, 1984) introduce este supuesto en la técnica DEA. Debido a que este último es, como veremos, el supuesto más apropiado para nuestro estudio, los distintos estimadores se explican bajo ese criterio. Utilizando notación de programación lineal, el modelo BCC puede plantearse de la siguiente manera: suponga que se tiene un número n de DMU donde cada DMUj, j = 1, 2, … n produce los mismos productos en diferentes cantidades yrj (r = 1, 2, … s) usando los mismos insumos, xij (i = 1,2, … m), también en diferentes cantidades. Formalmente, el modelo orientado a los insumos, asumiendo BCC, se formula como un problema de programación lineal de la siguiente manera (Bowlin, 1998):
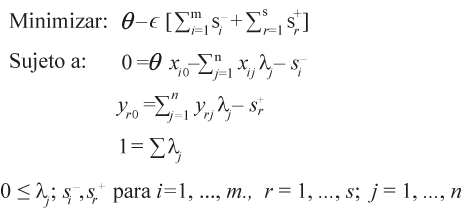
La técnica DEA asume convexidad estricta del conjunto de posibilidades de producción; i. e., todas las combinaciones que se encuentran en el conjunto de posibilidades teóricas son factibles. Una debilidad es que requiere de datos confiables (sin error de medición) y libres de la presencia de valores atípicos, lo cual es un supuesto fuerte para el caso de los servicios del agua.
2) FDH
Parte de los mismos principios del estimador DEA, pero relaja el supuesto de convexidad; solo son factibles las combinaciones definidas por los datos observados. FDH asume la libre disponibilidad en el conjunto de posibilidades de producción, determinado por las combinaciones o puntos de frontera observados (considerando que no hay error en la medición); con ello, reduce las posibilidades al área determinada de forma empírica por los datos observados (Deprins et al., 1984).
En este caso, el conjunto de producción asume una fuerte disponibilidad de ouput y libre disponibilidad de insumos, formando una envolvente poliédrica, pero no necesariamente convexa. En programación lineal, el estimador FDH con orientación a los insumos se plantea de manera formal de la siguiente manera (Marques y De Witte, 2011):
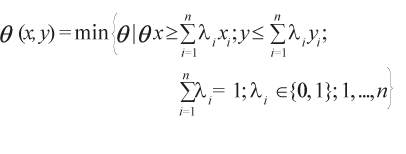
Estos dos primeros estimadores (DEA y FDH) son clasificados como determinísticos por sus supuestos sobre la determinación de las posibilidades de producción teóricas u observables derivadas de un conjunto de datos que, se asume, no registran errores de medición ni presencia de valores atípicos. Las estimaciones generadas por estos modelos tienen como principal limitación su alta sensibilidad a valores atípicos y a la presencia de errores en los datos (Cazals et al., 2002).
3) Orden m
A diferencia de los dos anteriores, este no envuelve todos los puntos de datos observados, por lo que se considera como una comparación (benchmarking) entre un número m (muestra) —cuyo tamaño a determinar depende, en parte, de la magnitud del grupo de DMU—; el procedimiento para obtenerlos se resume en cuatro etapas:
- Tener una muestra m aleatoria con reemplazo del grupo de DMU que satisface la condición de producir, al menos, tanto producto como la DMUi.
- Calcular la eficiencia parcial usando esa muestra.
- Repetir D veces los pasos 1 y 2.
- La eficiencia orden m se calcula como el promedio de las estimaciones obtenidas en el paso 3.
De manera formal, este estimador tiene como punto de partida, desde un modelo orientado a los insumos, el concepto función de insumos mínimos esperados (Cazals et al., 2002). En el caso más simple, considérese un entero fijo m ≥ 1. El límite inferior de X de orden m se define como el valor esperado del mínimo de m variables aleatorias x1, …, xm extraído de la función de distribución de X. La definición formal es la siguiente (Daraio y Simar, 2007, p. 68):
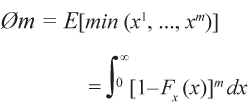
El valor φm es el nivel de insumo mínimo alcanzable esperado entre m DMU extraídos de la población de empresas que generan una cantidad determinada de producto. En general, y en términos económicos, se puede interpretar la frontera esperada de orden m, φm (Y), como el valor mínimo esperado de insumo alcanzable entre un número fijo (m) de DMU extraídas de la población que producen, al menos, un nivel de producto dado Y.
Debido al remuestreo aleatorio con reemplazo (paso 3), una DMUi puede o no estar disponible como su propio par. Por esa razón, los estimadores orden m con orientación a los insumos pueden exceder el valor de 1 y se consideran supereficientes por localizarse más allá de la frontera de posibilidades de producción estimada. Esa característica de los resultados del estimador permite identificar unidades que pueden ser clasificadas como valores atípicos, bien porque en realidad son tan eficientes que están fuera de la frontera de eficiencia estimada o por registrar errores en los datos.
4) Orden alfa (orden α)
Puede considerarse como una versión continua del estimador orden m. Se basa en la idea de que para cada empresa existe, en el conjunto de observaciones de comparación, una frontera de eficiencia cuantil que la toca, en la cual la compañía es eficiente (ya sea a lo largo de la dimensión de insumo o la de producto). Para evaluar la aptitud, se determina la frontera fijando primero la probabilidad (1 – α) de observar puntos por encima de este límite. El punto de referencia será la frontera de cuantiles orden-α definida como el nivel de insumo no superado por (1 – α) x 100 de las empresas que producen, al menos, el mismo nivel de resultados Y. Formalmente:
![]()
Por ejemplo, si el cuantil en el que la empresa es eficiente (en la orientación insumo) es α = 0.2, esto significa que hay 80 % (1 – 0.2 = 0.8) de las unidades en el conjunto de comparación que superan a la empresa considerada utilizando menos insumos. Cuando α < 100, algunas DMU pueden no estar envueltas por la frontera de posibilidades de producción estimada. Esto permite, al igual que orden m, identificar a las unidades que pueden ser valores atípicos (outliers).
5) BC
Los cuatro anteriores miden la eficiencia relativa a partir de la estimación de una frontera de esta derivada de un conjunto de datos observados y la comparación de cada unidad, ya sea con el grupo completo de unidades (DEA, FDH) o una muestra de ellos (orden m, orden α).
En el caso del estimador BC, se utilizan los datos observados para generar muestras de datos simulados mediante un método llamado bootstrap, el cual se basa en la idea de simular de manera repetida el proceso de generación de datos mediante remuestreo. Para implementar este enfoque, se proponen dos algoritmos bootstrap (ver planteamiento formal en Kneip et al., 2008). Mediante múltiples muestras simuladas a partir de un modelo teórico que trata de explicar la forma en la que se generaron los datos (llamado proceso generador de datos), se trata de reducir el sesgo que puede representar la presencia de valores atípicos o errores de medición en el conjunto de observaciones empíricas disponibles. El algoritmo I consiste en una simulación de datos que extrae n muestras en cada réplica para construir seudomuestras y obtener estimadores de eficiencia. El II es un proceso de suavizado (smoothing) de la distribución empírica de datos y de la frontera de producción; este se enfoca a suavizar la distribución empírica de datos observados, con lo cual se trata de reducir el efecto de los valores atípicos.
Preparación de la base de datos y el modelo para el análisis no paramétrico
La base de datos original incluye información de 2 668 OCTSA captados por los CE 2014 en México. Debido a que la aplicación de métodos no paramétricos requiere de valores no negativos en insumos y productos, para el análisis se consideraron solo valores estrictamente positivos. Así, se eliminaron 188 observaciones sin registro de redes de distribución de agua potable; también, los que reportaron cero conexiones (69) o cero ingresos (45); además, se identificaron las que mostraron cifras de conexiones inconsistentes para tratarse de OCTSA que abastecen a localidades con uso doméstico (i. e. un número de conexiones domésticas menor a la suma de conexiones comerciales e industriales, que sumaron 35); por último, se detectaron valores extremos inconsistentes, como los muy altos en longitud de redes que no corresponden con los de número de conexiones y personal (dos observaciones). La cantidad final de OCTSA con información completa para el cálculo de los estimadores fue de 2 349.
La selección de variables que se incluyeron en el modelo se basó en la revisión de la literatura especializada y la disponibilidad de datos. Se eligieron cuatro variables insumo disponibles en la base de datos; todos han sido utilizados en otros trabajos que analizan la actividad de servicios del agua: 1) la longitud de redes (en km), donde se sumaron las extensiones de tuberías de las redes primaria y secundaria reportadas; 2) los gastos en bienes y servicios (en pesos corrientes 2013), que se obtuvieron sumando los rubros: gastos por agentes físico-químicos, reactivos e insumos, por energía eléctrica y por suministro de agua en bloque; 3) el total de personal (número), que se formó con la suma del técnico y el administrativo dependiente de la razón social (contratado de forma directa, de planta, eventual y no renumerado, sujeto a la dirección y control del OCTSA) y no dependiente de la razón social; y 4) el volumen captado de agua (en miles de m3), el cual se calculó mediante la suma de volúmenes de agua superficial y del subsuelo que obtuvo de manera directa cada OCTSA.
Como variable producto, en esta investigación se utilizó el número de conexiones domésticas, que ya ha sido usado como tal en otros trabajos. Definir a este como la variable producto y no, por ejemplo, a los ingresos obtenidos, responde al reconocimiento que los OCTSA en México son organizaciones no lucrativas y su principal objetivo es abastecer de agua entubada, drenaje y saneamiento a todas las personas que habitan su área de influencia. En efecto, de acuerdo con los datos de los CE 2014, una proporción importante de operadores (35 %) genera ingresos menores a sus gastos, lo que claramente afecta la posibilidad de utilizar las entradas de dinero como variable producto, pues no es realista asumir que estos tienen como propósito mantener un nivel dado de ingresos u optimizarlos. Es necesario mencionar que esta elección no implica que la finalidad de los OCTSA deba ser sola o principalmente la cobertura y lograr el máximo posible de conexiones. De manera ideal, deberían incluirse otros aspectos (variables), como la calidad del agua distribuida, la continuidad de los servicios, la asequibilidad de las tarifas y la equidad en acceso, entre otros. Aunque esto es técnicamente posible, pues una de las ventajas de los métodos no paramétricos consiste, de hecho, en incluir varios productos, no fue factible generar estas variables con la información disponible.
En resumen, el modelo general que se utiliza en este trabajo se define por las cuatro variables insumo mencionadas y una variable producto. El cuadro 2 muestra que estas registran un amplio rango de valores; por ejemplo, se tienen OCTSA que captan desde mil hasta más de mil millones de metros cúbicos de agua; también, se registran otros que funcionan con un solo trabajador y hasta uno con casi 11 mil empleados.
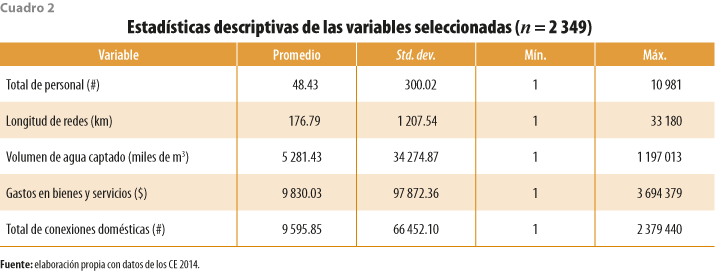
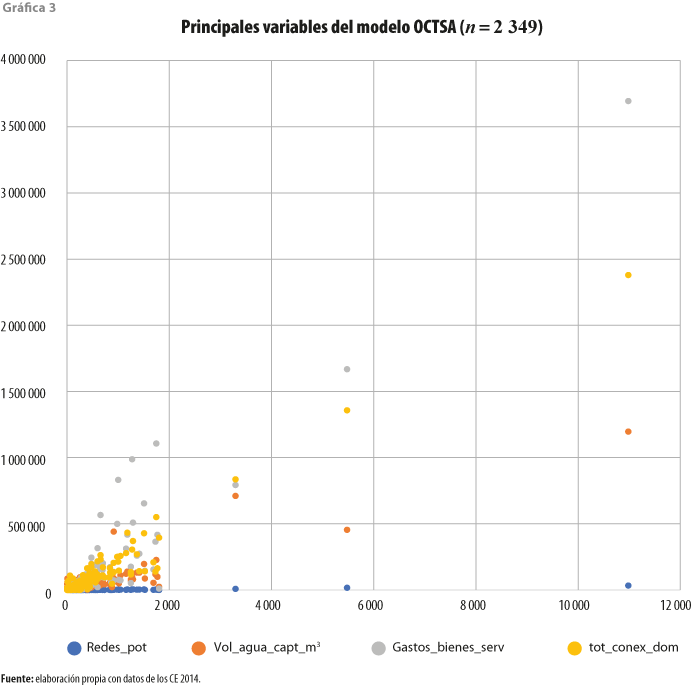
Es relevante notar que se puede esperar la presencia de errores no intencionales o, incluso, intencionales en el registro de los datos (como es conocido y por diversas razones, en México los OCTSA pueden reportar datos modificados a propósito). La presencia de valores inusualmente altos puede observarse en la gráfica 3; mientras que el total de personal y la longitud de redes no aparecen tan dispersas, las variables volumen de agua captado, gastos en bienes y servicios y total de conexiones domésticas reportan cifras extremas.[5]
El tamaño de la base de datos analizada (2 349 OCTSA) y la estimación de eficiencia con métodos no paramétricos robustos requieren de cálculos intensivos que, por fortuna, se pueden realizar mediante distintos programas estadísticos. En este trabajo se obtuvieron los cinco estimadores definidos utilizando programas de usuario que se implementan en el programa Stata v. 15.
Como se mencionó en la sección anterior; para este modelo se asume una orientación hacia los insumos. La segunda especificación necesaria es el supuesto de rendimientos a escala; para definir el tipo de estos utilizado en el modelo, se aplicó un test, en el cual se prueba como hipótesis nula que la tecnología es de rendimientos constantes (CRS, por sus siglas en inglés) H0 = CRS. Un segundo cuestionario prueba la hipótesis nula de rendimientos de escala no crecientes (NIRS, por sus siglas en inglés) con la hipótesis alternativa (H1) de rendimientos de escala variables (VRS, por sus siglas en inglés).[6] Los resultados obtenidos se reportan en el cuadro 3.
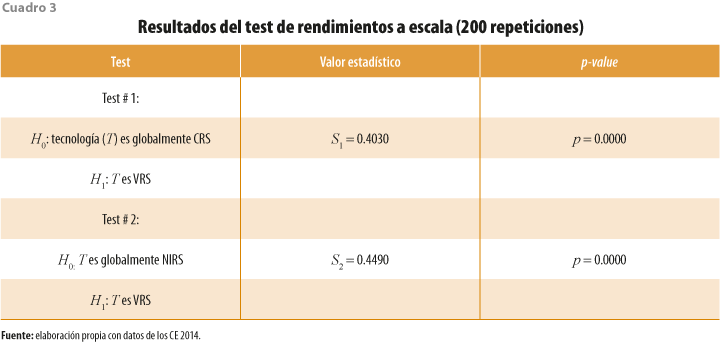
El valor estadístico S1 es el cociente entre las medidas promedio de eficiencia técnica bajo el supuesto de las tecnologías VRS y CRS. Si la hipótesis nula es cierta, entonces la distancia promedio entre las fronteras VRS y CRS es pequeña (Badunenko y Mozharovskyi, 2016); si la alternativa es verdadera, la distancia promedio entre las fronteras VRS y CRS es grande. Si en el test # 1 se rechaza la H0, se procede entonces al # 2; si la hipótesis nula H0 para este test es verdadera, entonces la distancia promedio entre las fronteras VRS y NIRS es pequeña. De acuerdo con los resultados, las dos hipótesis nulas se rechazan, lo cual indica que los OCTSA operan bajo una tecnología de escala variable (VRS). Un resultado adicional de estos tests es que se clasifica a cada OCTSA como eficiente o ineficiente en su escala de operación actual. Otro dato interesante que se puede obtener es que 68.7 % de los OCTSA en México son ineficientes en escala y 31.3 % (736) operan de manera eficiente en escala.
Resultados de los cinco estimadores
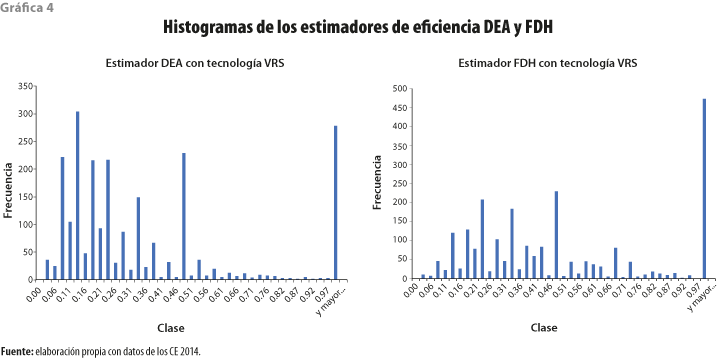
La implementación del análisis no paramétrico se inició con los dos estimadores que utilizan los datos del grupo de observaciones completo de OCTSA; el DEA, que asume que todas las combinaciones de insumos teóricas son posibles y que no existen valores atípicos ni errores en los datos; y el FDH, que acepta como combinaciones de insumo factibles solo a las derivadas de las observaciones y que no existen errores de medición ni valores atípicos en los datos. Los resultados se comparan en el cuadro 4 y la gráfica 4.
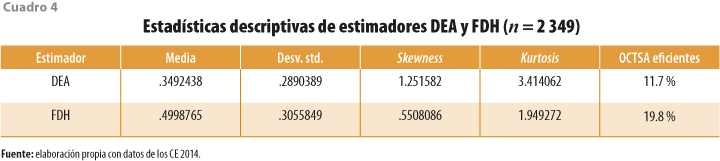
Lo primero que se puede notar es que la eficiencia promedio del estimador FDH es mayor que el del DEA, lo cual es una consecuencia lógica derivada de que la frontera de eficiencia estimada con FDH se basa solo en los valores observados del grupo de OCTSA. Se encontró, también, que la proporción de unidades eficientes o en la frontera de producción (con estimadores = 1) se incrementa de 275 (11.7 %) a 465 (19.8 %). Es razonable esperar, como lo indica la literatura, que estos dos primeros estimadores reflejen el sesgo de la presencia de valores atípicos y/o errores en los datos, lo que implica una posible sobrevaluación de la eficiencia.
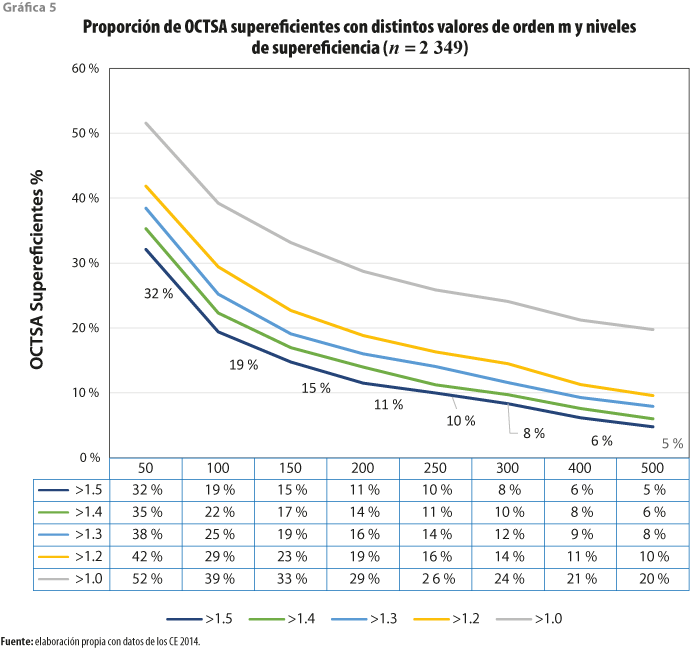
El primer estimador que trata de solventar las limitaciones de los dos determinísticos (DEA y FDH) es el de orden m. Para su implementación (debido a que se basa en la evaluación de eficiencia por muestras y dado que no existe un parámetro m definido a priori), se prueban distintos valores de m, en un rango de 100 hasta 500; esto es, cada OCTSA fue comparado con muestras aleatorias de 100 a 500 unidades, con 200 repeticiones para obtener el estimador de eficiencia (θ). Como se explica en este trabajo, por su forma de cálculo, el estimador de orden m genera valores de eficiencia mayores a 1; a los operadores con esos valores se les denomina supereficientes. Ya que tampoco hay un criterio predefinido para determinar un valor que sirva como parámetro de supereficiencia, elegimos 1.5 para que un OCTSA pueda ser considerado valor atípico. Un organismo clasificado con este valor utiliza, al menos, 50 % menos de insumos que las unidades de la submuestra m con la que se compara para producir un nivel dado de producto.
En la gráfica 5 puede observarse que con m = 50, la tercera parte de OCTSA resultan supereficientes (con puntuación > 1.5), mientras que con m = 500, la proporción se reduce a 5 por ciento. Un criterio para identificar a los organismos que son verdaderos valores atípicos es su permanencia como supereficientes, aun con altos valores de m; en este caso, al menos 5 % de operadores se mantienen como tales a altos valores de m (m = 500) y con un criterio extremo del estimador de eficiencia (θ > 1.5).
En lugar de definir muestras con un número de OCTSA determinado (como lo hace el estimador orden m), el α utiliza cuartiles (1 – α) como criterio para comparar la eficiencia. Con el uso de este estimador se propone evaluar el impacto de los valores atípicos y errores en la base de datos de OCTSA en la proporción de supereficiencia. Para ello, se analiza un rango de valores de α entre 0 y 1.
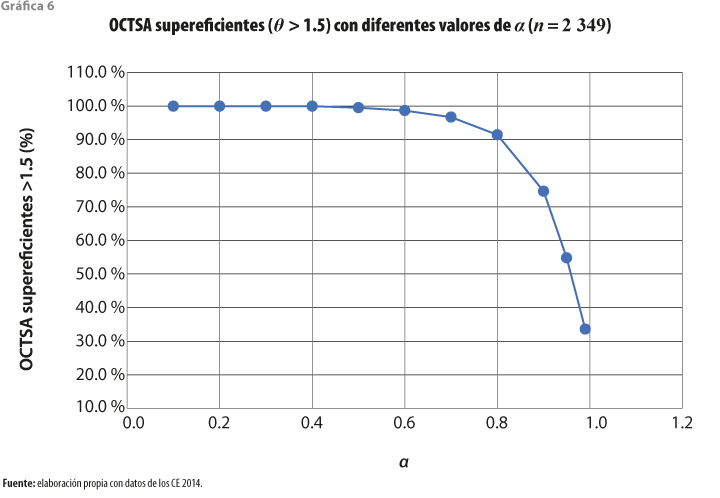
En la gráfica 6 se presentan los porcentajes de operadores supereficientes (θ > 1.5) a diferentes valores de α. Los resultados muestran que cuando α = .80, la proporción de estos OCTSA disminuye de manera más rápida (de 90 % a poco más de 75 %). No obstante, los valores promedio estimados de eficiencia con orden α y la proporción de OCTSA supereficientes son muy altos, esto implica que una gran proporción de organismos se ubica fuera de la frontera estimada de posibilidades de producción. En otros términos, el estimador orden α es altamente afectado por la presencia de valores atípicos o errores, los estimadores de eficiencia de orden α que resultan son sobreestimados.
Los resultados de los estimadores con fronteras parciales se pueden utilizar para identificar las unidades del grupo de operadores con valores atípicos. Para ello, definimos como criterio las puntuaciones de eficiencia > 1.5 que se generaron para cada uno de los 2 349 OCTSA de la base de datos; con los valores clave de m = 400 para orden m y para orden α = .80. En este caso, se identificaron 145 OCTSA como valores atípicos.[7] Una opción es eliminar a los atípicos y, para el resto, se podría estimar FDH, con lo que se obtendría un ranking de eficiencia sin el sesgo de observaciones atípicas. Esto implica, sin embargo, perder 6 % de los organismos con información completa que no podrían ser clasificados. De manera alternativa, se optó por aplicar el BC mediante la simulación de datos (bootstrap).
Un supuesto clave para poder definir el proceso generador de datos (necesario para la simulación de muestras que usa el estimador BC) es que las n observaciones en el grupo de datos analizado (i. e. estimaciones de eficiencia) sean variables aleatorias independientes e idénticamente distribuidas (i. i. d.) en el conjunto convexo posible. Por lo tanto, y como paso previo requerido para la estimación del BC, se realizó la prueba de independencia de las estimaciones de eficiencia (con 999 repeticiones y 95 % de nivel de confianza). El resultado de la prueba confirmó que las estimaciones de eficiencia son variables aleatorias independientes con un valor p = 0.0000.[8] Para la estimación BC, se utilizó el método bootstrap homogéneo suavizado con 999 repeticiones (para un resumen de sus resultados, ver cuadro 5). La eficiencia promedio es 0.31, con 182 OCTSA clasificados como eficientes. Un dato notable es que la proporción global de OCTSA eficientes (7.7 %) disminuye de manera destacada cuando se compara con los estimadores determinísticos DEA (11.7 %) y FDH (19.8 %).
La corrección del sesgo que logra el estimador BC se observa en el hecho de que la eficiencia promedio estimada de los 145 OCTSA identificados como valores atípicos por orden m y orden α fue de 0.69. Este es un claro resultado de la corrección por sesgo de valores atípicos que logra este estimador y la principal ventaja que aporta con respecto a los otros cuatro que, como se observó con los resultados obtenidos, son afectados por la presencia de valores atípicos, manteniendo altas proporciones de operadores supereficientes o que se encuentran más allá de la frontera de producción estimada.

Una vez que se confirma la corrección de sesgo lograda por los estimadores BC, podemos hacer diferentes análisis de los valores de eficiencia estimados. Un aspecto de interés particular en este trabajo es comparar la eficiencia técnica de los OCTSA por tamaño de población atendida. Para ello, se organiza la información por tamaño de localidad atendida en cinco secciones: menores a 2 500 (consideradas como rurales), entre 2 500 y 20 mil; entre 20 001 y 50 mil; entre 50 mil y 1 millón y mayores a 1 millón de habitantes. El cuadro 6 muestra que, en promedio, el grupo de OCTSA con mayor población atendida (más de 1 millón de habitantes) registra el mejor promedio de eficiencia (0.50); este resultado era de esperarse, dado que las ciudades y zonas metropolitanas con mayor población son las que pueden captar mayores ingresos y reciben, también, inversiones más elevadas, así como financiamiento público. Sin embargo, debe notarse que ninguno de los 10 operadores en localidades mayores a 1 millón de habitantes es 100 % eficiente (i. e. en uno o más de los insumos podría mejorar).
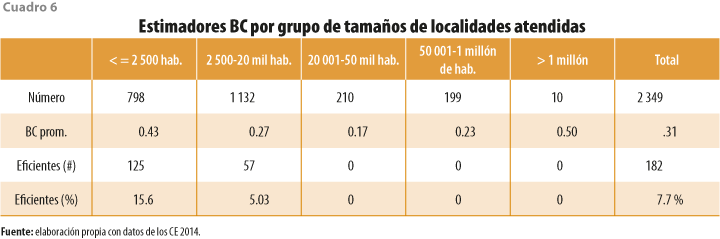
Un resultado también interesante es que, en contraste con los OCTSA de áreas urbanas grandes, 125 de localidades rurales se reportan como 100 % eficientes; esta cifra puede parecer contraintuitiva pues, como se sabe, la cobertura de servicios de agua y saneamiento en zonas rurales de México es baja y, por lo general, de mala calidad. Sin embargo, debe tomarse en cuenta que este análisis se refiere a la eficiencia técnica, entendida como las mejores combinaciones de insumos para dar servicio a un número dado de conexiones; no se analizan aspectos de calidad o cobertura. Por lo tanto, este resultado puede explicarse como consecuencia de que los organismos muy pequeños cuentan con los insumos en cantidades mínimas tanto en gastos, personal, volumen captado y redes, por lo que están obligados a optimizarlos.
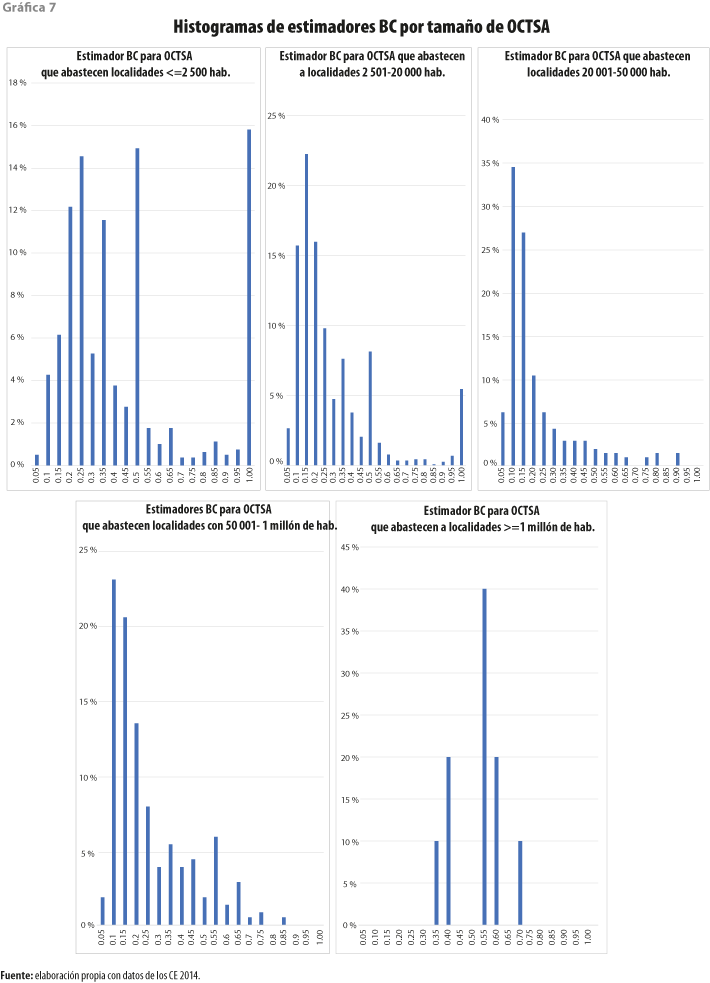
En la gráfica 7 se muestran los porcentajes de OCTSA por niveles estimados de eficiencia con BC. Como puede verse, en los cuatro grupos menores a 1 millón de habitantes registran bajas eficiencias técnicas (por debajo de 0.5). Otro aspecto importante es que las distribuciones de los estimadores de eficiencia de los operadores de localidades más pequeñas (menos de 2 500 habitantes) y las más grandes (mayores de 1 millón) son los que difieren más en su distribución con respecto a los otros tres grupos.
Conclusiones
En este trabajo se muestra el potencial que la base de datos de los Censos Económicos en México tiene para el análisis de eficiencia técnica en los servicios del agua. La aplicación de cinco estimadores no paramétricos nos permite concluir que el BC reduce de forma significativa el sesgo generado por la presencia de valores atípicos y errores de medición o reporte en los servicios del agua. Como era de esperar, los estimadores determinísticos (DEA y FDH) sobreestiman el número de unidades eficientes como consecuencia de la presencia de valores atípicos. Por otra parte, los resultados de los estimadores basados en fronteras parciales (orden m y orden α) permitieron identificar 145 OCTSA supereficientes, los cuales o bien son realmente muy eficientes, o esa supereficiencia se debe a datos erróneos registrados de forma voluntaria o involuntaria. En todo caso, ambos resultados sugieren la necesidad de mejorar el proceso de validación de datos.
Una observación relevante para la política pública se deriva de la prueba de rendimientos de escala; se observa que, al menos la tercera parte de los OCTSA en México funcionan en la actualidad a una escala ineficiente; una vez identificados esos organismos pueden establecerse medidas operativas tendientes a ajustar su escala al tamaño apropiado en aspectos incluidos en el análisis, como gastos en bienes y servicios, así como la cantidad de personal. Estos aspectos específicos hacen necesaria, también, una mejor regulación y la implementación de mecanismos de profesionalización de los servicios de agua y saneamiento en México.
Los resultados de los estimadores corregidos por sesgo confirman la percepción usual de que los OCTSA más grandes (mayores a 1 millón) son, en general, el grupo más eficiente (siete de los 10 registran un estimador mayor a 0.50); sin embargo, ninguno de ellos (cuando se analizan con el estimador corregido por sesgo) es considerado 100 % eficiente. Este dato implica consecuencias importantes pues, aunque los organismos de las áreas urbanas con mayor población son usualmente los que registran mejores indicadores de desempeño tradicionales (p. e. eficiencia comercial o buena capacidad de cobrar lo facturado; o eficiencia física, un menor volumen de agua no facturada), el hecho de que no sean eficientes en su totalidad sugiere que se están desperdiciando recursos. En específico, esto significa que en los operadores de las grandes áreas urbanas en México no se hace un uso eficiente de algunos de los insumos incluidos en este análisis (volumen de agua captado, gastos, personal o redes) con los consecuentes impactos ambientales y costos económicos que esto trae.
Los resultados también informan que 15 % de los OCTSA rurales es 100 % eficiente. Esto es importante, pues sugiere que los organismos de las localidades rurales registran buenas prácticas relacionadas con el uso de las variables incluidas en este modelo (gastos en bienes y servicios, total de personal, volumen captado de agua y longitud de redes). Sin embargo, se debe tener cuidado con esto, pues no implica que se logre buena calidad de los servicios o cobertura adecuada en localidades rurales. En general, esa es una limitación del análisis hecho en este trabajo, derivado sobre todo de la falta de indicadores apropiados y compatibles con la base de datos utilizada de calidad del agua, calidad y continuidad en los servicios y aquellos relacionados con el derecho humano al agua, como equidad y asequibilidad en las tarifas.
Por otro lado, las estimaciones de eficiencia corregidas por sesgo logradas con el estimador BC permiten la posibilidad de otro tipo de análisis; por ejemplo, el efecto de variables externas (fuentes de agua, nivel de subsidio, disponibilidad del líquido y participación privada, entre otras) en el nivel de eficiencia técnica. Estos temas se proponen para una agenda futura de investigación.
Conocer la eficiencia técnica de los OCTSA del país tiene diferentes implicaciones para los diversos niveles de administración de los servicios del agua. En el ámbito local, un operador puede identificar un referente de eficiencia (por ejemplo, dentro del mismo estado) para mejorar sus prácticas. Para instancias por entidades, como las comisiones estatales del agua, puede utilizarse como instrumento para identificar las mejores prácticas de los OCTSA eficientes o estrategias para la profesionalización de los organismos clasificados como ineficientes. A nivel federal, podría mejorar los criterios para la asignación de recursos públicos a los servicios del vital líquido. En México, la política enfocada a mejorar la cobertura de servicios básicos de agua se aplica a través del Programa de Agua Potable, Drenaje y Tratamiento (PROAGUA), en el cual se parte, como primer criterio de priorización, de la Declaratoria de las Zonas de Atención Prioritaria, determinadas para municipios y localidades con elevados porcentajes de población en situación de pobreza y con alto grado de rezago social. Otros son el número de habitantes, acciones que corresponden a recomendaciones de derechos humanos y actividades que contribuyen al ahorro de energía. Se podría asegurar un mayor beneficio si se pondera de forma positiva a los OCTSA que muestran una mayor eficiencia en el uso de los recursos, tanto financieros (p. e. el manejo en gastos en bienes e insumos) como del agua (eficiencia en uso de volúmenes captados) y personal empleado. De otra manera, los destinados a localidades con rezago social, pero donde operan organismos ineficientes podría no mejorar la cobertura de los servicios y mucho menos otros aspectos como la calidad y asequibilidad de los mismos. Asegurar un mejor manejo del recurso e insumos mediante una mejor regulación, la profesionalización de los servicios y una mayor transparencia contribuirán a lograr el objetivo de cumplir con los derechos humanos a agua potable y saneamiento en el país.
______________
Fuentes
Aguilar-Benítez I. “Viabilidad financiera de los servicios del agua: una comparación de tres pares de ciudades en la frontera México-Estados Unidos”, en: Aguilar-Benítez, I. (coord.). Los servicios del agua en el norte de México: gestión, manejo financiero y aspectos socio-ambientales. Tijuana, Colef/Colson, 2011.
Anwandter, L., & T. Jr. Ozuna. “Can public sector reforms improve the efficiency of public water utilities?”, in: Environment and Development Economics. 7(04), 2002. doi:10.1017/s1355770x02000414.
Badunenko, Oleg and Pavlo Mozharovskyi. “Nonparametric Frontier Analysis Using Stata”, in: The Stata Journal. Vol. 16, no. 3, Sept. 2016, pp. 550-589, doi:10.1177/1536867X1601600302.
Banker, R. D., A. Charnes & W. W. Cooper. “Some models for estimating technical and scale inefficiencies in data envelopment analysis”, in: Management Science. 30(9), 1984, pp 1078-1092.
Bowlin, W. “Measuring Performance: An Introduction to Data Envelopment Analysis (DEA)”, in: The Journal of Cost Analysis. 15:2, 1998, pp. 3-27, doi: 10.1080/08823871.1998.10462318.
Cazals, C., Florens and Simar. “Nonparametric frontier estimation: a robust approach”, in: Journal of Econometrics. 106, (1), 2002, pp. 1-25.
Charnes, A., W. W. Cooper y E. Rhodes. “Measuring the efficiency of decision making units”, in: European Journal of Operational Research. 1978, pp. 429-444.
Cooper W., L. M. Seiford y Zhu. “Handbook on Data Envelopment Analysis”, in: International Series in Operations Research & Management Science. Second edition. Volume 164, 2011.
Cooper W., L. M. Seiford y K. Tone. Introduction to Data Envelopment Analysis and its Uses. With DEA-Solver Software and References. Springer, 2006.
Daraio, Cinzia & Léopold Simar. Advanced Robust and Nonparametric Methods in Efficiency Analysis: Methodology and Applications. Springer, 2007. doi:10.1007/978-0-387-35231-2.
Deprins, D. and H Tulkens. “Measuring Labour Efficiency in Post Offices”, in: Marchand, M. and H. Tulkens (eds.). The Performance of Public Enterprises: Concepts and Measurement North-Holland. 1984, pp. 243-267.
Daouia, A., & L. Simar. “Nonparametric efficiency analysis: A multivariate conditional quantile approach”, in: Journal of Econometrics. 140(2), 2007, pp. 375-400. doi:10.1016/j.jeconom.2006.07.002.
Fox, K., R. Hill & W. Diewert. “Identifying Outliers in Multi-Output Models”, in: Journal of Productivity Analysis. 22(1/2), 2004, pp. 73-94.
Kneip, A., L. Simar & P. Wilson. “Asymptotics and Consistent Bootstraps for DEA Estimators in Nonparametric Frontier Models”, in: Econometric Theory. 24(6), 2008, pp. 1663-1697.
Marques, R. C. & K. de Witte. “Is big better? On scale and scope economies in the Portuguese water sector”, in: Economic Modelling. 28(3), 2011, pp. 1009-1016. doi:10.1016/j.econmod.2010.11.014.
Picazo-Tadeo, A. J., F. González-Gómez & F. J. Sáez-Fernández. “Accounting for operating environments in measuring water utilities’ managerial efficiency”, in: The Service Industries Journal. 29(6), 2009, pp. 761-773. doi:10.1080/02642060802190300.
Simar, L. and P. W. Wilson. “Non-parametric tests of returns to scale”, in: European Journal of Operational Research. 139(1), 2002, pp. 115-132.
Tauchmann, Harald. “Partial Frontier Efficiency Analysis”, in: The Stata Journal. Vol. 12, no. 3, Sept. 2012, pp. 461-478, doi:10.1177/1536867X1201200309.
[1] Existen varios tipos de eficiencia que se pueden aplicar a los servicios del agua: técnica, operativa o económica. En este trabajo nos enfocamos en el análisis de la primera, que se entiende, en general, como la combinación óptima de insumos para lograr un nivel dado de producto. La segunda es la más común y se analiza por medio de indicadores de desempeño, p. e. el número de empleados por cada mil tomas o el porcentaje de dinero facturado que efectivamente se cobra. Cuando se incluye el aspecto menor costo y se propone generar el mayor producto posible, se habla de eficiencia económica.
[2] A lo largo del texto se utilizan los términos insumo y producto para referirnos a los términos en inglés inputs y outputs, aunque debe notarse que el primero se refiere a factores de producción y el segundo, a resultados de un proceso. De esta manera, aunque referirse a número de conexiones como producto no es estrictamente correcto, se hace para facilitar la exposición.
[3] Este trabajo se deriva de los resultados del proyecto de investigación Hacia una gestión integral del agua por cuenca hidrológica: un análisis de la disponibilidad y usos, financiado por el Consejo Nacional de Ciencia y Tecnología (CONACYT) en la convocatoria Problemas Nacionales 2014, número 248 719.
[4]La actividad de captación, tratamiento y suministro de agua se reporta con la clasificación 2221, de acuerdo con el Sistema de Clasificación Industrial de América del Norte (SCIAN) 2013 México. El uso de microdatos para el análisis de este trabajo se realizó en el Laboratorio de Microdatos del Instituto Nacional de Estadística y Geografía (INEGI) y fue registrado como proyecto LM588. El autor agradece el apoyo del personal del Instituto.
[5] Aunque no existe una definición estándar para valores atípicos, dos aspectos que son comunes en las distintas definiciones son: que son valores extremos en la muestra y que son suficientemente extremos como para tener poca probabilidad de ocurrencia (Fox et al., 2004).
[6] Ver Simar y Wilson, 2002 y Badunenko y Mozharovskyi, 2016. Para una explicación detallada de los programas utilizados en Stata, ver Badunenko y Mozharovskyi, 2016 y Tauchmann, 2012.
[7] Una limitación de la fuente de información es que debido a que procede de los CE aplicados por el INEGI, los datos se manejan observando los principios de confidencialidad y reserva, por lo que no se cuenta con el nombre oficial de cada OCTSA, pero sí se tiene un identificador, por lo que es posible comparar el resultado individual para cada estimador.
[8] El comando utilizado para estimar indicadores BC (teradialbc) proporciona inferencia estadística para tres tipos de bootstrap: 1) homogéneo suavizado, 2) heterogéneo suavizado y 3) submuestreo (heterogéneo). En este caso aplicamos el tipo 1, siguiendo los resultados del test de independencia. El resultado de la prueba de independencia indicó que se puede usar bootstrap homogéneo.

Propuesta metodológica: Índice de Infraestructura Urbana para el diagnóstico urbanístico sobre el traslado de personas mayores de 60 años en tres AGEB de la Jurisdicción Sanitaria Magdalena Contreras

Estandarización de las áreas geoestadísticas básicas urbanas para 100 ciudades del Sistema Urbano Nacional